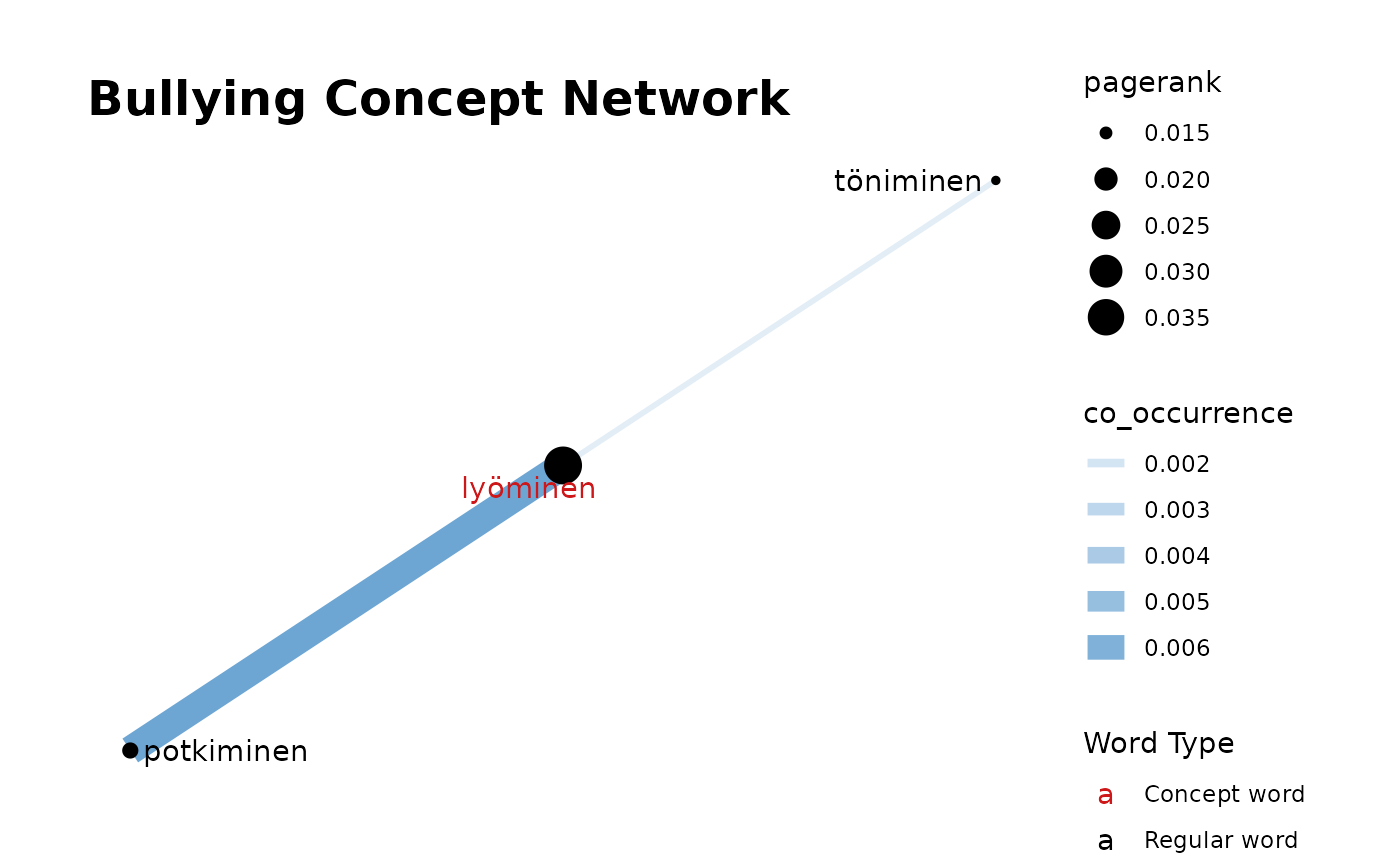
This function takes a string of terms (separated by commas) or a single term and, using `textrank_keywords()` from `textrank` package, filters data based on `pos_filter` and finds words connected to search terms. Then it plots a Concept Network based on the calculated weights of these terms and the frequency of co-occurrences.
Usage
fst_concept_network(
data,
concepts,
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = NULL
)Arguments
- data
A dataframe of text in CoNLL-U format, with optional additional columns.
- concepts
List of terms to search for, separated by commas.
- threshold
A minimum number of occurrences threshold for 'edge' between searched term and other word, default is `NULL`. Note, the threshold is applied before normalisation.
- norm
The method for normalising the data. Valid settings are `"number_words"` (the number of words in the responses), `"number_resp"` (the number of responses), or `NULL` (raw count returned, default, also used when weights are applied).
- pos_filter
List of UPOS tags for inclusion, default is `NULL` to include all UPOS tags.
- title
Optional title for plot, default is `NULL` and a generic title ("TextRank extracted keyword occurrences") will be used.
Examples
data <- fst_child
con <- "kiusata, lyöminen"
pf <- c("NOUN", "VERB", "ADJ", "ADV")
title <- "Bullying Concept Network"
fst_concept_network(data, concepts = con, pos_filter = pf, title = title)