InDetail5-AnalysisExample1
Source:vignettes/web_only/InDetail5-AnalysisExample1.Rmd
InDetail5-AnalysisExample1.RmdIntroduction
This tutorial goes into further details demonstrating the use of the
package, covering functions in r/02_data_exploration.R and
r/03_concept_network.R. The intention is to provide an
example where some initial analysis of an open-ended survey question is
used to inform the settings and concept words of the Concept Network
plot. Then, we demonstrate how the Concept Network settings can be
fine-tuned to produce plots which are more persuasive visualisations of
your findings.
Installation of package.
Once the package is installed, you can load the
finnsurveytext package as below: (Other required packages
such as dplyr and stringr will also be
installed if they are not currently installed in your environment.)
The Data
We’re looking again at the FSD2821 Young People’s Views on Development Cooperation 2012 (FSD2821 Nuorten ajatuksia kehitysyhteistyöstä 2012) survey which is provided as sample data with the package.
Development Cooperation Data
- data/dev_coop.rda
There are 3 open-ended questions we look at within this data and we
will set the threshold and other function arguments to be
suit each question.
The open-ended questions
- q11_1 Jatka lausetta: Kehitysmaa on maa, jossa… (Avokysymys)
- q11_1 Continue the sentence: A developing country is a country where… (Open question)
- q11_2 Jatka lausetta: Kehitysyhteistyö on toimintaa, jossa…
(Avokysymys)
- q11_2 Continue the sentence: Development cooperation is an activity in which… (Open question)
- q11_3 Jatka lausetta: Maailman kolme suurinta ongelmaa ovat…
(Avokysymys)
- q11_3 Continue the sentence: The world’s three biggest problems are… (Open question)
Demonstration of analysis
Format
First, we will format our data data.
dev_coop <- dev_coop
q11_1 <- fst_prepare(data = dev_coop,
question = 'q11_1',
id = 'fsd_id',
model = "ftb",
stopword_list = "nltk",
weights = 'paino',
add_cols = NULL,
manual = FALSE,
manual_list = "")
#> Downloading udpipe model from https://raw.githubusercontent.com/jwijffels/udpipe.models.ud.2.5/master/inst/udpipe-ud-2.5-191206/finnish-ftb-ud-2.5-191206.udpipe to /home/runner/work/finnsurveytext/finnsurveytext/vignettes/web_only/finnish-ftb-ud-2.5-191206.udpipe
#> - This model has been trained on version 2.5 of data from https://universaldependencies.org
#> - The model is distributed under the CC-BY-SA-NC license: https://creativecommons.org/licenses/by-nc-sa/4.0
#> - Visit https://github.com/jwijffels/udpipe.models.ud.2.5 for model license details.
#> - For a list of all models and their licenses (most models you can download with this package have either a CC-BY-SA or a CC-BY-SA-NC license) read the documentation at ?udpipe_download_model. For building your own models: visit the documentation by typing vignette('udpipe-train', package = 'udpipe')
#> Downloading finished, model stored at '/home/runner/work/finnsurveytext/finnsurveytext/vignettes/web_only/finnish-ftb-ud-2.5-191206.udpipe'
q11_2 <- fst_prepare(data = dev_coop,
question = 'q11_2',
id = 'fsd_id',
model = "ftb",
stopword_list = "nltk",
weights = 'paino',
add_cols = NULL,
manual = FALSE,
manual_list = "")
q11_3 <- fst_prepare(data = dev_coop,
question = 'q11_3',
id = 'fsd_id',
model = "ftb",
stopword_list = "nltk",
weights = 'paino',
add_cols = NULL,
manual = FALSE,
manual_list = "")Here we’ll print the first 10 rows of the the raw data and then one of the the processed datasets (Q11_1).
| fsd_id | q11_1 | q11_2 | q11_3 | paino | gender | region | year_of_birth | education_level |
|---|---|---|---|---|---|---|---|---|
| 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). Ja niitä ei ole riittävästi | varmaan koitetaan kehittää em | saastuminen ja luonnonvarojen liikakäyttö, nälänhätä ja ylikansoittuminen | 0.5440 | Female | Etelä-Suomi | 1992 | NA |
| 2 | on kurjuutta ja nälänhätää, asiat eivät ole vielä kehittyneet, lapset eivät pääse kouluun, tytöillä on huonompi asema kuin pojilla. | pyritään auttamaan? | ihmiskauppa, nälänhätä ja sodat/turvattomuus | 0.7171 | Female | Pohjois- ja Itä-Suomi | 1994 | Matriculation examination |
| 3 | jokaisella ei ole turvattua toimeentuloa ja jossa todella huomaa koulutuksen arvon. | autetaan ja näytetään ihmisille tie parempaan tulevaisuuteen heidän oman työnsä tuloksena. | kouluttamattomuus, nälkä ja puhtaan veden puute. | 0.6240 | Female | Helsinki-Uusimaa | 1994 | Matriculation examination |
| 4 | kehityksen taso ei ole yhtä korkea kuin kehittyneissä maissa | yleensä haitataan kehitysmaan kehittymistä | öljy, raha, se fakta että ei olla vielä päästy asumaan muualla kuin tällä yhdellä planeetalla | 0.3401 | NA | Länsi-Suomi | NA | NA |
| 5 | asiat ovat vielä huonossa jamassa ja apua tarvitaan | eriarvoisuus, sodat, nälänhätä tietyissä maissa | 0.6240 | Female | Helsinki-Uusimaa | 1993 | Upper secondary vocational qualification |
| doc_id | paragraph_id | sentence_id | sentence | token_id | token | lemma | upos | xpos | feats | head_token_id | dep_rel | deps | misc | weight |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 1 | elämiseen | eläminen | NOUN | N,Sg,Ill | Case=Ill|Number=Sing | 2 | nmod | NA | NA | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 2 | tarvittavat | tarvita | VERB | V,Pass,PcpVa,Pl,Nom | Case=Nom|Number=Plur|PartForm=Pres|VerbForm=Part|Voice=Pass | 3 | acl | NA | NA | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 3 | perusasiat | perusasia | NOUN | N,Pl,Nom | Case=Nom|Number=Plur | 5 | nsubj | NA | NA | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 5 | kehittymättöneet | kehittymättöa | VERB | V,Act,PcpNut,Pl,Nom | Case=Nom|Number=Plur|PartForm=Past|VerbForm=Part|Voice=Act | 0 | root | NA | NA | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 7 | esim. | esim. | PART | Pcle,Abbr | Abbr=Yes | 8 | dep | NA | NA | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 8 | vesi | vesi | NOUN | N,Sg,Nom | Case=Nom|Number=Sing | 5 | obj | NA | SpaceAfter=No | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 10 | talo | talo | NOUN | N,Sg,Nom | Case=Nom|Number=Sing | 8 | conj | NA | SpaceAfter=No | 0.544 |
| 1 | 1 | 1 | elämiseen tarvittavat perusasiat ovat kehittymättöneet (esim. vesi, talo, ruoka). | 12 | ruoka | ruoka | NOUN | N,Sg,Nom | Case=Nom|Number=Sing | 8 | conj | NA | SpaceAfter=No | 0.544 |
| 1 | 1 | 2 | Ja niitä ei ole riittävästi | 5 | riittävästi | riittävästi | ADV | Adv | NA | 4 | advmod | NA | SpacesAfter= | 0.544 |
| 10 | 1 | 1 | asiat ei ole niin hyvin kuin täällä rahallisesti mitattuna | 1 | asiat | asia | NOUN | N,Pl,Nom | Case=Nom|Number=Plur | 5 | nsubj:cop | NA | NA | 0.544 |
Initial EDA
To begin with, let’s look at the differences between the types of reponses we get for each of these open-ended questions by using some of the EDA functions. (For further details into these functions, see “Tutorial2-Data_Exploration”)
First, let’s consider these functions:
-
fst_summarise()- This table will indicate response rate, and word counts. -
fst_pos()- This table counts the number and proportion of words with each part-of-speech tag. -
fst_length_summary()- This table gives the average and quartile values of lengths of responses in words and sentences.
The differences in the types of responses can be seen in the exploratory data analysis results below:
Summarise
knitr::kable(
fst_summarise(data = q11_1, desc = "Q11_1")
)| Description | Respondents | No Response | Proportion | Total Words | Unique Words | Unique Lemmas |
|---|---|---|---|---|---|---|
| Q11_1 | 921 | 24 | 0.97 | 4257 | 1513 | 1065 |
knitr::kable(
fst_summarise(data = q11_2, desc = "Q11_2")
)| Description | Respondents | No Response | Proportion | Total Words | Unique Words | Unique Lemmas |
|---|---|---|---|---|---|---|
| Q11_2 | 907 | 34 | 0.96 | 4407 | 1270 | 893 |
knitr::kable(
fst_summarise(data = q11_3, desc = "Q11_3")
)| Description | Respondents | No Response | Proportion | Total Words | Unique Words | Unique Lemmas |
|---|---|---|---|---|---|---|
| Q11_3 | 920 | 25 | 0.97 | 4192 | 1132 | 994 |
Remarks:
- All 3 questions have a high (97/98%) response rate.
- Q11_1 contains the most unique words.
- All 3 questions have a similar number of unique lemmas.
POS Summary
| UPOS | UPOS_Name | Count | Proportion |
|---|---|---|---|
| ADJ | adjective | 664 | 0.157 |
| ADP | adposition | 65 | 0.015 |
| ADV | adverb | 399 | 0.094 |
| AUX | auxiliary | 29 | 0.007 |
| CCONJ | coordinating conjunction | 4 | 0.001 |
| DET | determiner | 79 | 0.019 |
| INTJ | interjection | 0 | 0.000 |
| NOUN | noun | 2201 | 0.520 |
| NUM | numeral | 2 | 0.000 |
| PART | particle | 160 | 0.038 |
| PRON | pronoun | 47 | 0.011 |
| PROPN | proper noun | 18 | 0.004 |
| PUNCT | punctuation | 0 | 0.000 |
| SCONJ | subordinating conjunction | 4 | 0.001 |
| SYM | symbol | 2 | 0.000 |
| VERB | verb | 552 | 0.130 |
| X | other | 7 | 0.002 |
| UPOS | UPOS_Name | Count | Proportion |
|---|---|---|---|
| ADJ | adjective | 353 | 0.081 |
| ADP | adposition | 55 | 0.013 |
| ADV | adverb | 178 | 0.041 |
| AUX | auxiliary | 20 | 0.005 |
| CCONJ | coordinating conjunction | 4 | 0.001 |
| DET | determiner | 66 | 0.015 |
| INTJ | interjection | 2 | 0.000 |
| NOUN | noun | 1940 | 0.444 |
| NUM | numeral | 3 | 0.001 |
| PART | particle | 62 | 0.014 |
| PRON | pronoun | 20 | 0.005 |
| PROPN | proper noun | 7 | 0.002 |
| PUNCT | punctuation | 0 | 0.000 |
| SCONJ | subordinating conjunction | 11 | 0.003 |
| SYM | symbol | 1 | 0.000 |
| VERB | verb | 1648 | 0.377 |
| X | other | 3 | 0.001 |
| UPOS | UPOS_Name | Count | Proportion |
|---|---|---|---|
| ADJ | adjective | 389 | 0.093 |
| ADP | adposition | 24 | 0.006 |
| ADV | adverb | 64 | 0.015 |
| AUX | auxiliary | 3 | 0.001 |
| CCONJ | coordinating conjunction | 3 | 0.001 |
| DET | determiner | 28 | 0.007 |
| INTJ | interjection | 2 | 0.000 |
| NOUN | noun | 3286 | 0.789 |
| NUM | numeral | 5 | 0.001 |
| PART | particle | 29 | 0.007 |
| PRON | pronoun | 12 | 0.003 |
| PROPN | proper noun | 31 | 0.007 |
| PUNCT | punctuation | 0 | 0.000 |
| SCONJ | subordinating conjunction | 0 | 0.000 |
| SYM | symbol | 1 | 0.000 |
| VERB | verb | 278 | 0.067 |
| X | other | 12 | 0.003 |
Remarks:
- Nouns are the most common word type across all 3 questions.
- Q11_1 also commonly contains adjectives, adverbs and nouns.
- Q11_2 has a similar number of nouns and verbs, and then a smaller number of adjectives and adverbs.
- Q11_3 also has a lot of adjectives and verbs but few adverbs.
Length Summary
knitr::kable(
fst_length_summary(
data = q11_1,
desc = "Q11_1",
incl_sentences = TRUE
)
)| Description | Respondents | Mean | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|---|
| Q11_1- Words | 921 | 6.515 | 1 | 3 | 5 | 8 | 33 |
| Q11_1- Sentences | 921 | 1.058 | 1 | 1 | 1 | 1 | 4 |
knitr::kable(
fst_length_summary(
data = q11_2,
desc = "Q11_2",
incl_sentences = TRUE
)
)| Description | Respondents | Mean | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|---|
| Q11_2- Words | 907 | 5.398 | 1 | 3 | 4 | 7 | 30 |
| Q11_2- Sentences | 907 | 1.019 | 1 | 1 | 1 | 1 | 3 |
knitr::kable(
fst_length_summary(
data = q11_3,
desc = "Q11_2",
incl_sentences = TRUE
)
)| Description | Respondents | Mean | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|---|
| Q11_2- Words | 920 | 5.515 | 1 | 4 | 5 | 6 | 32 |
| Q11_2- Sentences | 920 | 1.015 | 1 | 1 | 1 | 1 | 3 |
Remarks:
- All 3 questions have most responses being one sentence.
- Each question has a longest response of about 30 words and most responses of about 5 words.
Most common words and n-grams
Now, lets create some tables of the most common words, bigrams and trigrams using the following functions:
Top Words
fst_freq(
data = q11_1,
number = 10,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_1"
)
#> Note:
#> Words with equal occurrence are presented in alphabetical order.
#> By default, words are presented in order to the `number` cutoff word.
#> This means that equally-occurring later-alphabetically words beyond the cutoff word will not be displayed.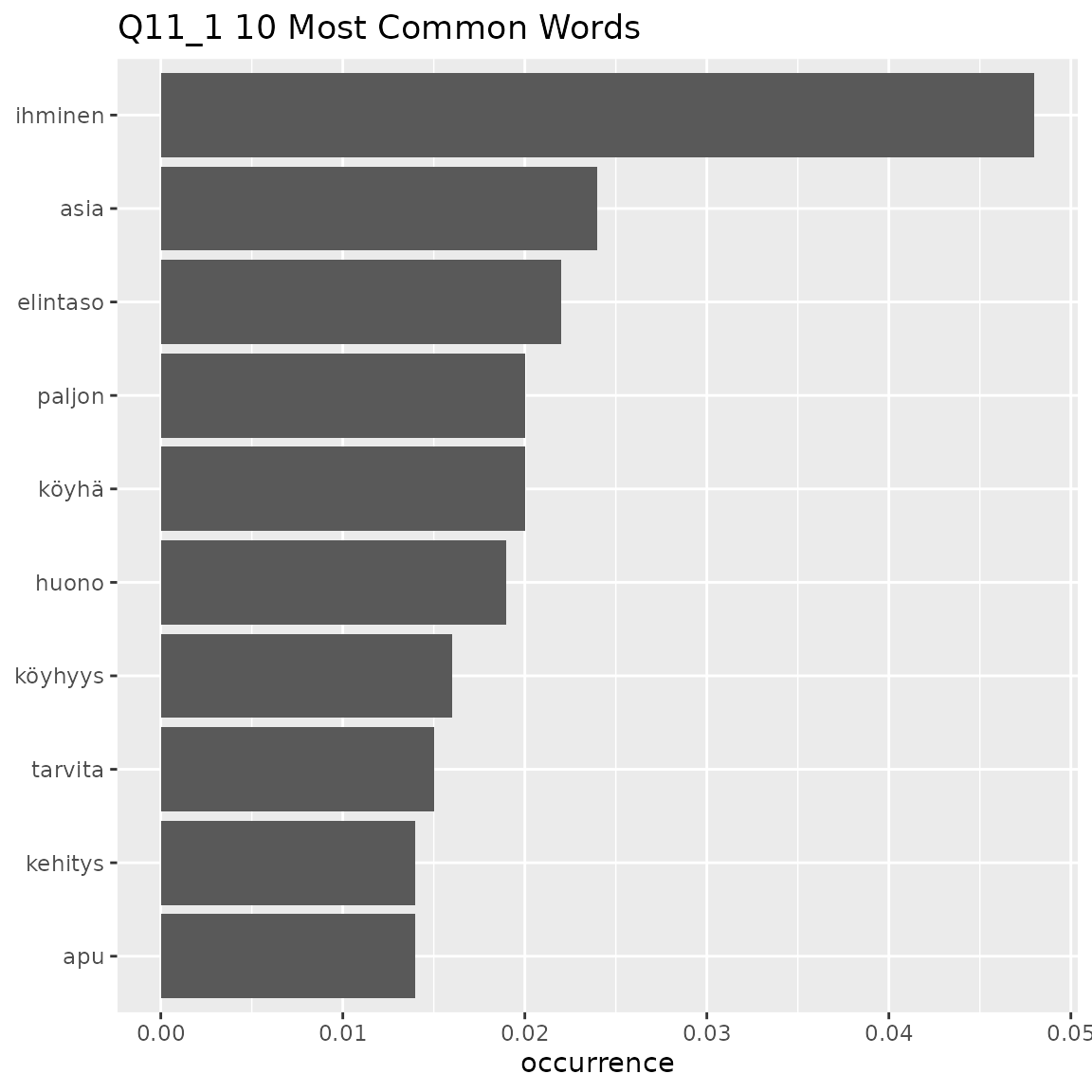
fst_freq(
data = q11_2,
number = 10,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_2"
)
#> Note:
#> Words with equal occurrence are presented in alphabetical order.
#> By default, words are presented in order to the `number` cutoff word.
#> This means that equally-occurring later-alphabetically words beyond the cutoff word will not be displayed.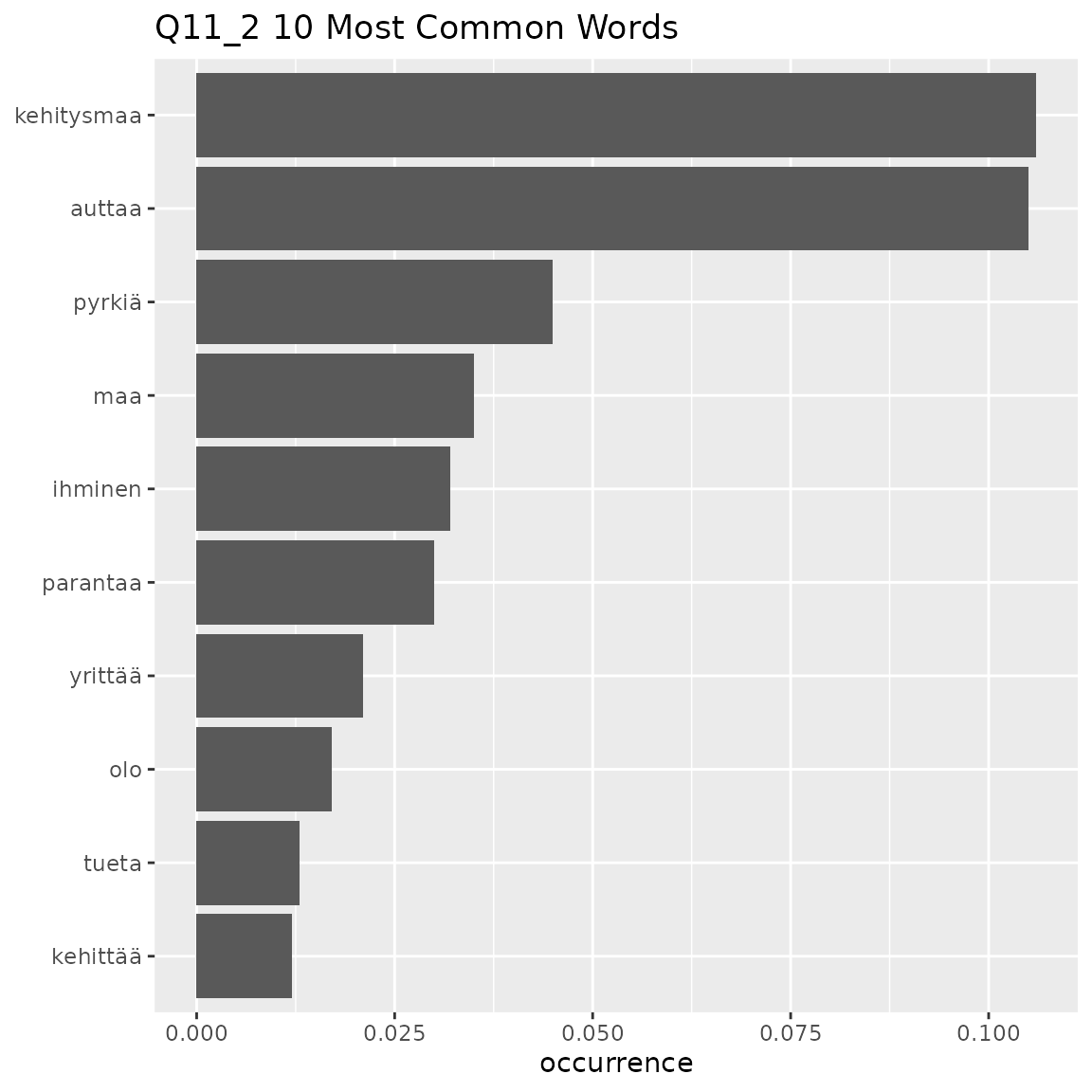
fst_freq(
data = q11_3,
number = 10,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_3"
)
#> Note:
#> Words with equal occurrence are presented in alphabetical order.
#> By default, words are presented in order to the `number` cutoff word.
#> This means that equally-occurring later-alphabetically words beyond the cutoff word will not be displayed.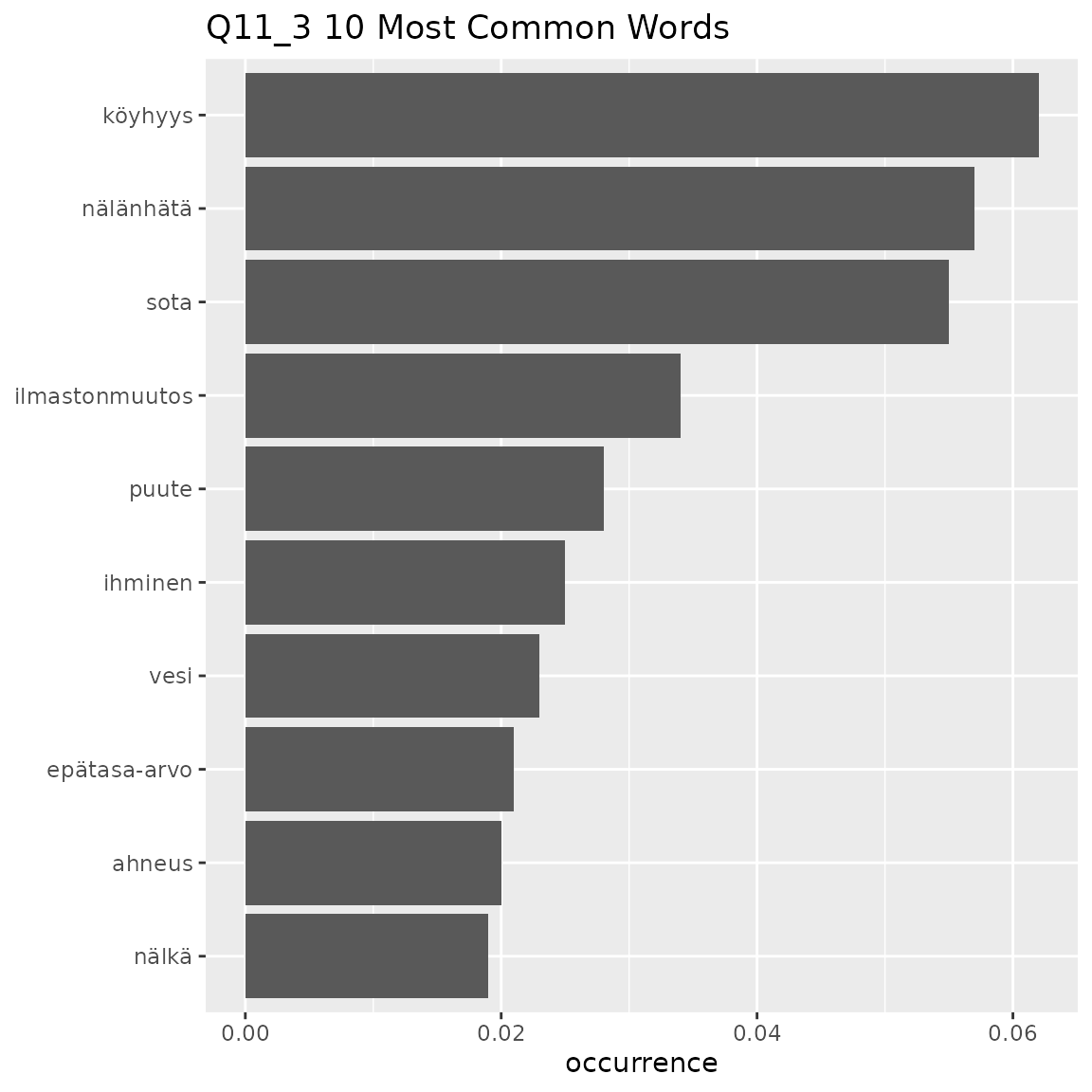
(We leave the default for norm her so “occurrence” is
based on the number of words in the set of responses for each
question.)
Here we can see that there is a clear ‘top’ set of words in each question:
- Q11_1: ‘ihminen’ (man)
- Q11_2: ‘kehitysmaa’ (developing country), ‘auttaa’ (helps)
- Q11_3: ‘köyhyys’ (poverty), ‘nälänhätä’ (famine), ‘sota’ (war)
Bi-grams and Trigrams
Here we look at common sets of two or three words.
fst_ngrams(
data = q11_1,
number = 10,
ngrams = 2,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_1"
)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.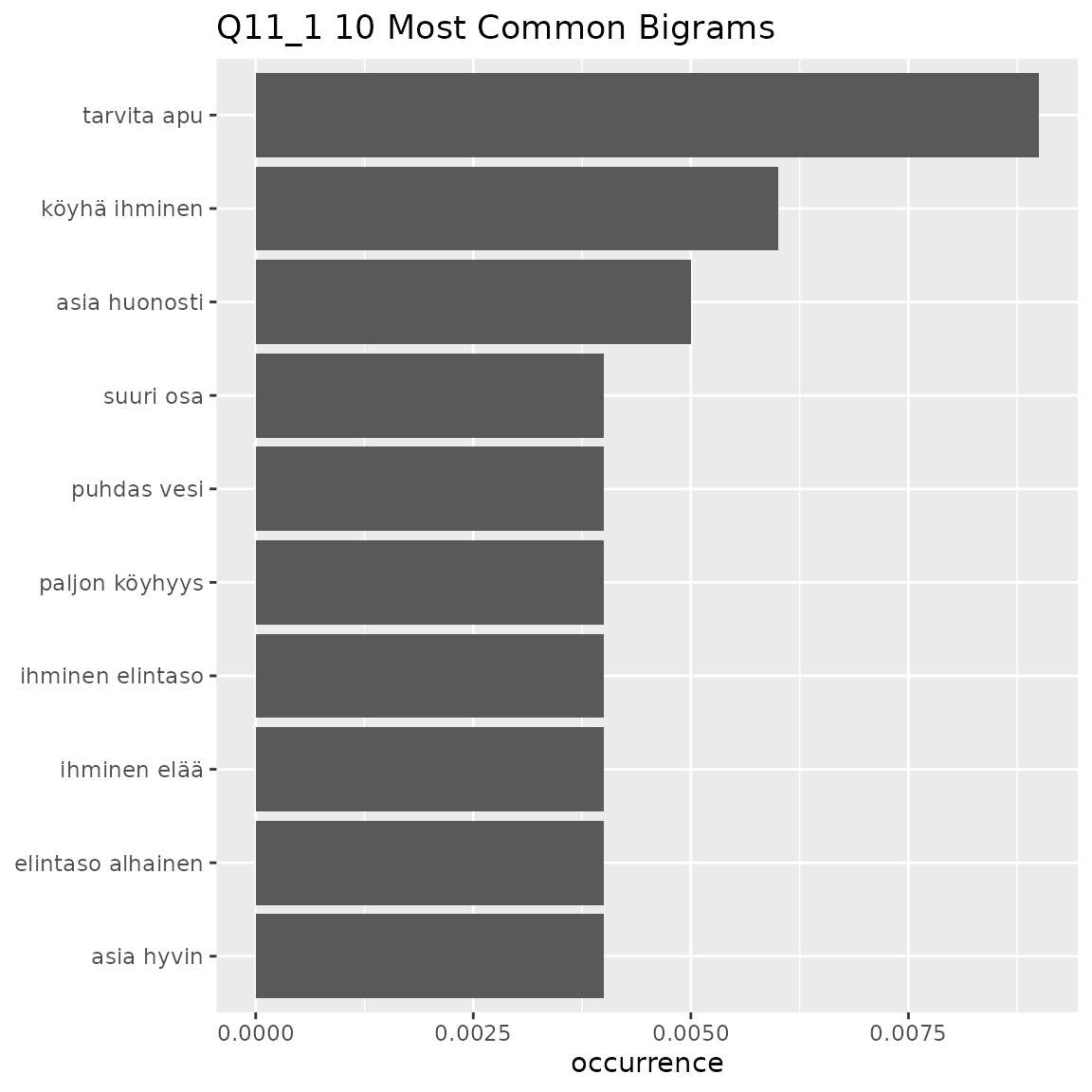
fst_ngrams(
data = q11_1,
number = 10,
ngrams = 3,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_1"
)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.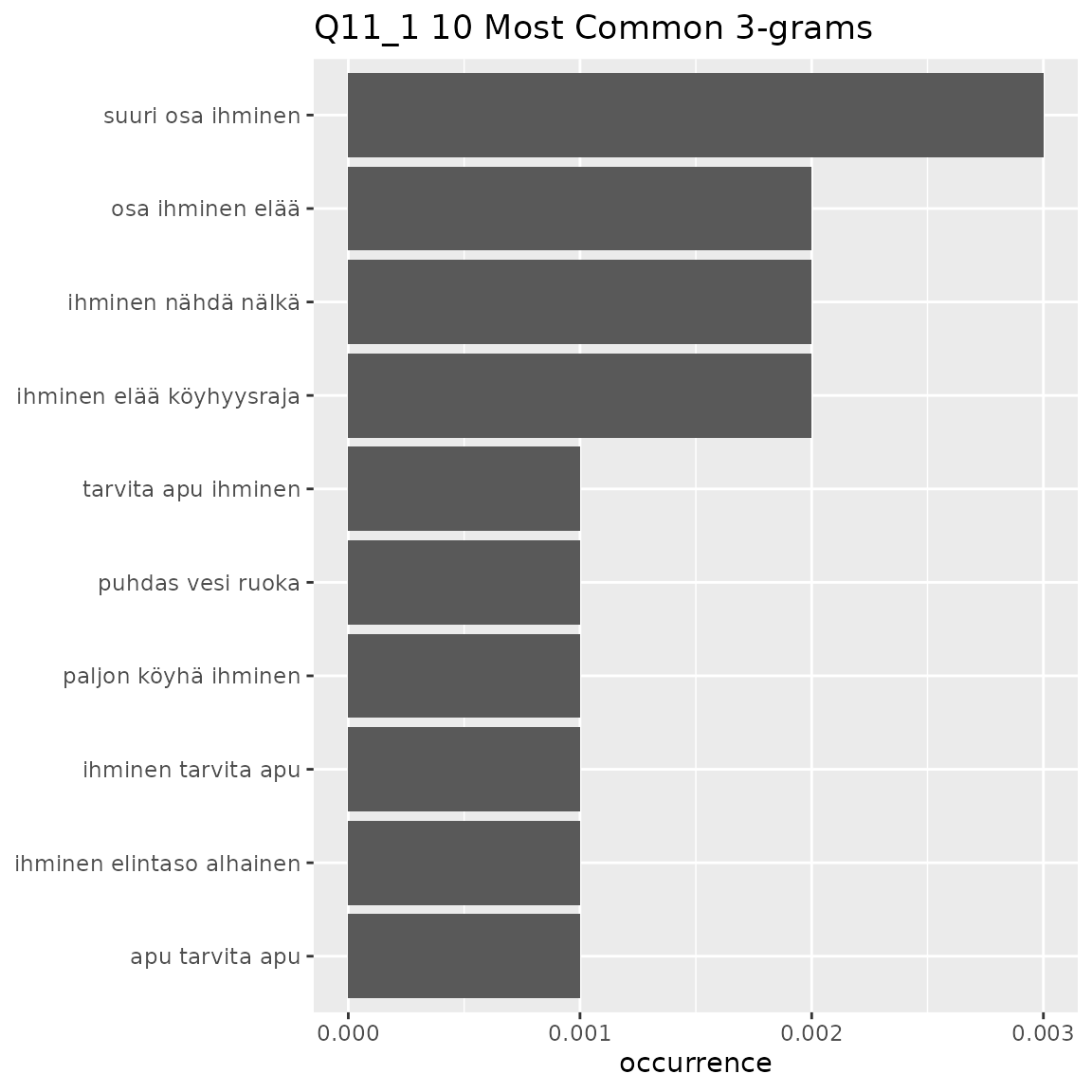
fst_ngrams(
data = q11_2,
number = 10,
ngrams = 2,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_2"
)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.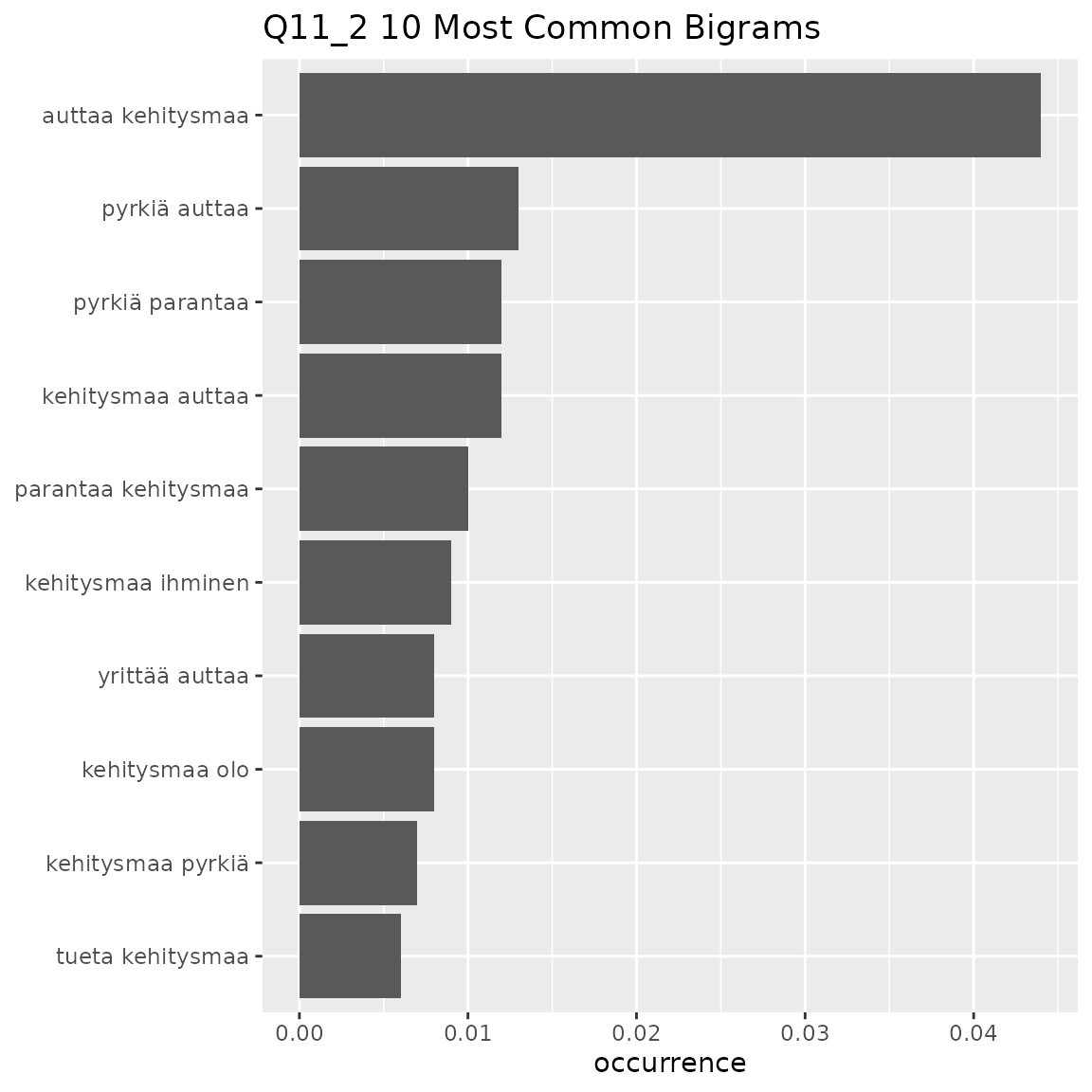
fst_ngrams(
data = q11_2,
number = 10,
ngrams = 3,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_2"
)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.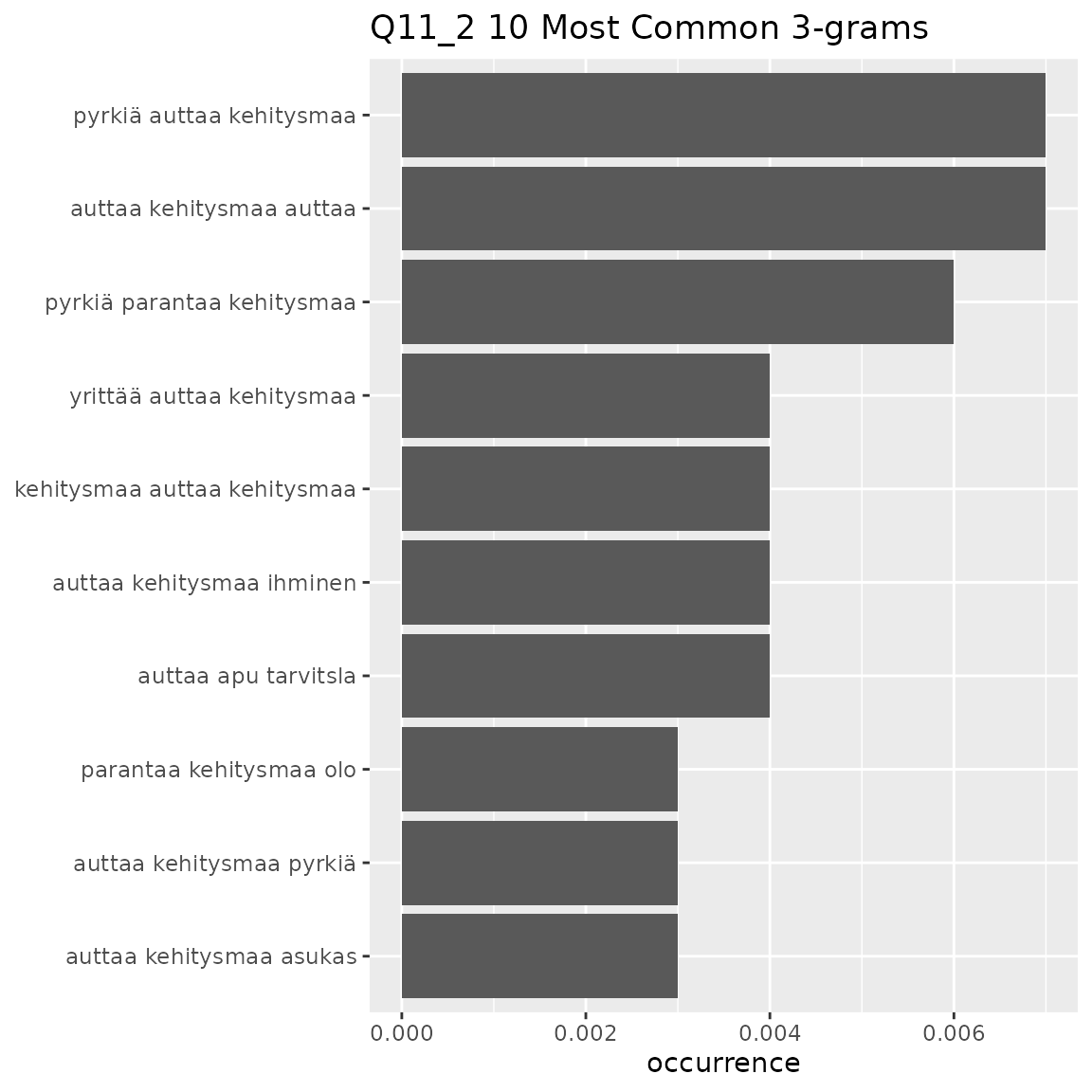
fst_ngrams(
data = q11_3,
number = 10,
ngrams = 2,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_3"
)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.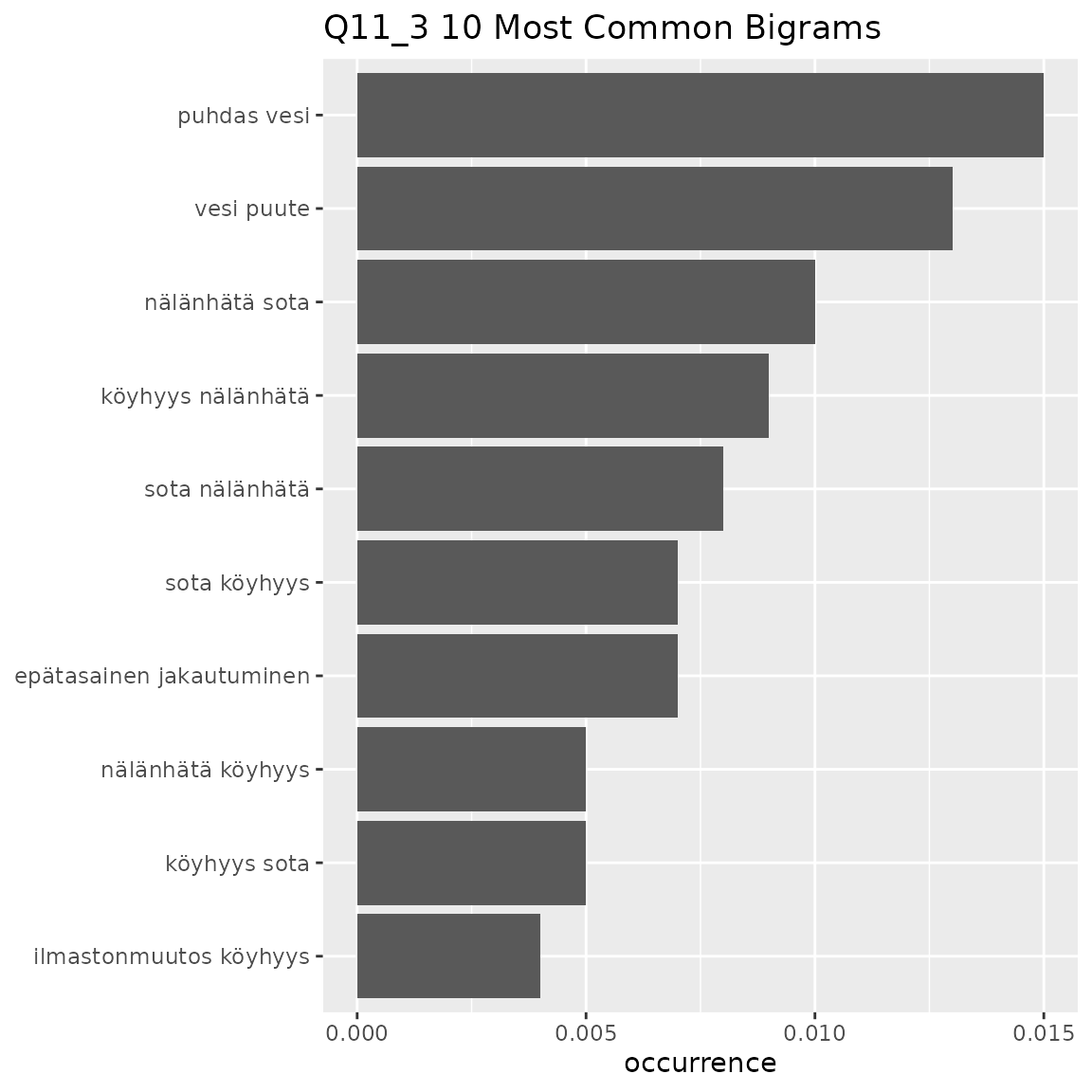
fst_ngrams(
data = q11_3,
number = 10,
ngrams = 3,
norm = "number_words",
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
strict = TRUE,
name = "Q11_3"
)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.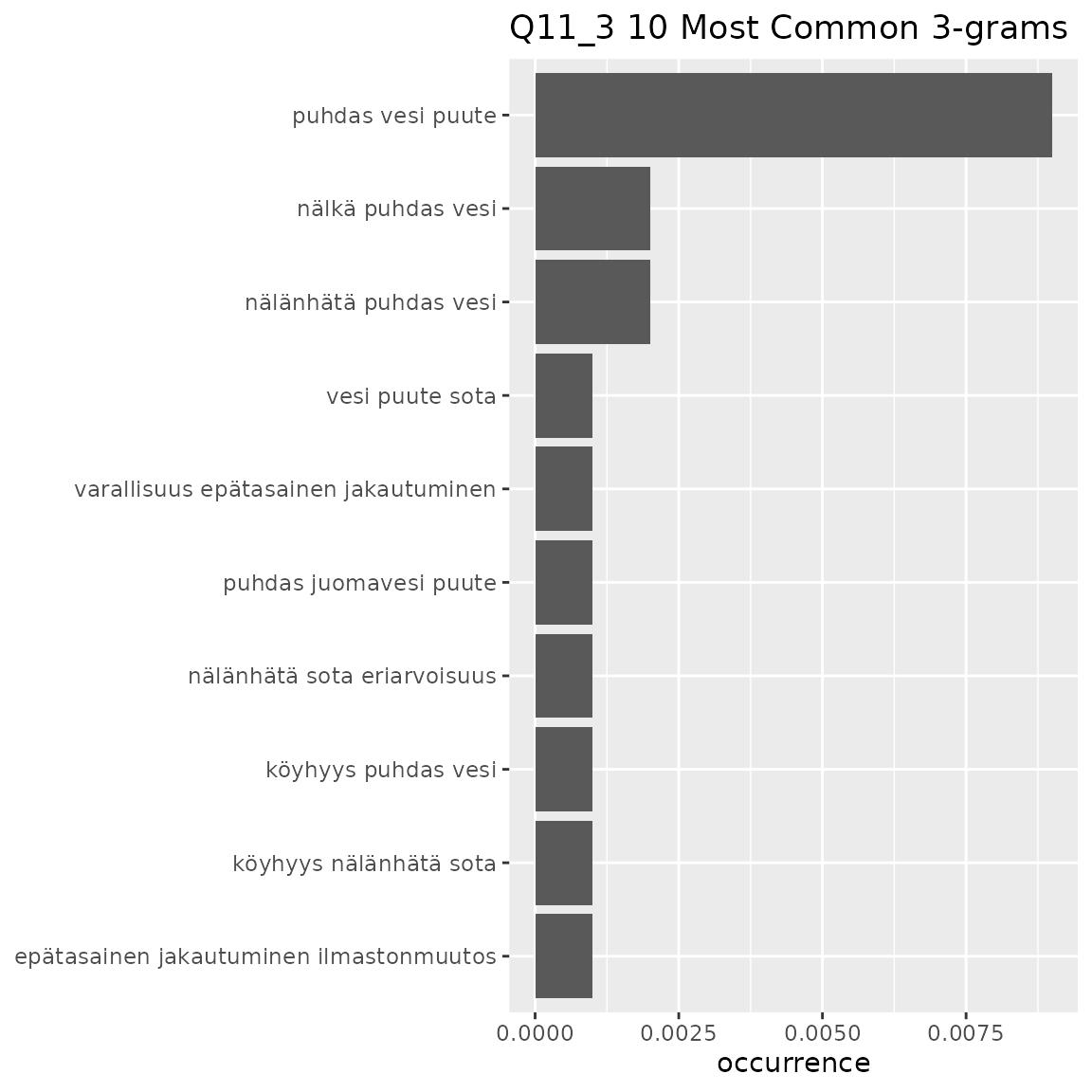
Recall the open-ended questions
- q11_1 Jatka lausetta: Kehitysmaa on maa, jossa… (Avokysymys)
- q11_1 Continue the sentence: A developing country is a country where… (Open question)
- q11_2 Jatka lausetta: Kehitysyhteistyö on toimintaa, jossa…
(Avokysymys)
- q11_2 Continue the sentence: Development cooperation is an activity in which… (Open question)
- q11_3 Jatka lausetta: Maailman kolme suurinta ongelmaa ovat…
(Avokysymys)
- q11_3 Continue the sentence: The world’s three biggest problems are… (Open question)
Common themes raised in bigrams and trigrams:
- Q11_1
- Discussion about groups of people living in poverty
- ‘suuri osa ihminen’, ‘tarvita apu’, ‘ihminen nähdaä nälkä’, ‘osa ihminen elää’, ihminen elää köyhyysraja’, ‘köyhä ihminen’
- Q11_2
- Themes about helping countries develop
- ‘auttaa kehitysmaa’, ‘pyrkiä auttaa kehitysmaa’, ‘auttaa kehitysmaa auttaa’
- Q11_3
- Concern about lack of water, clean water
- ‘vesi puute’, ‘puhdas vesi’, ‘puhdas vesi puute’
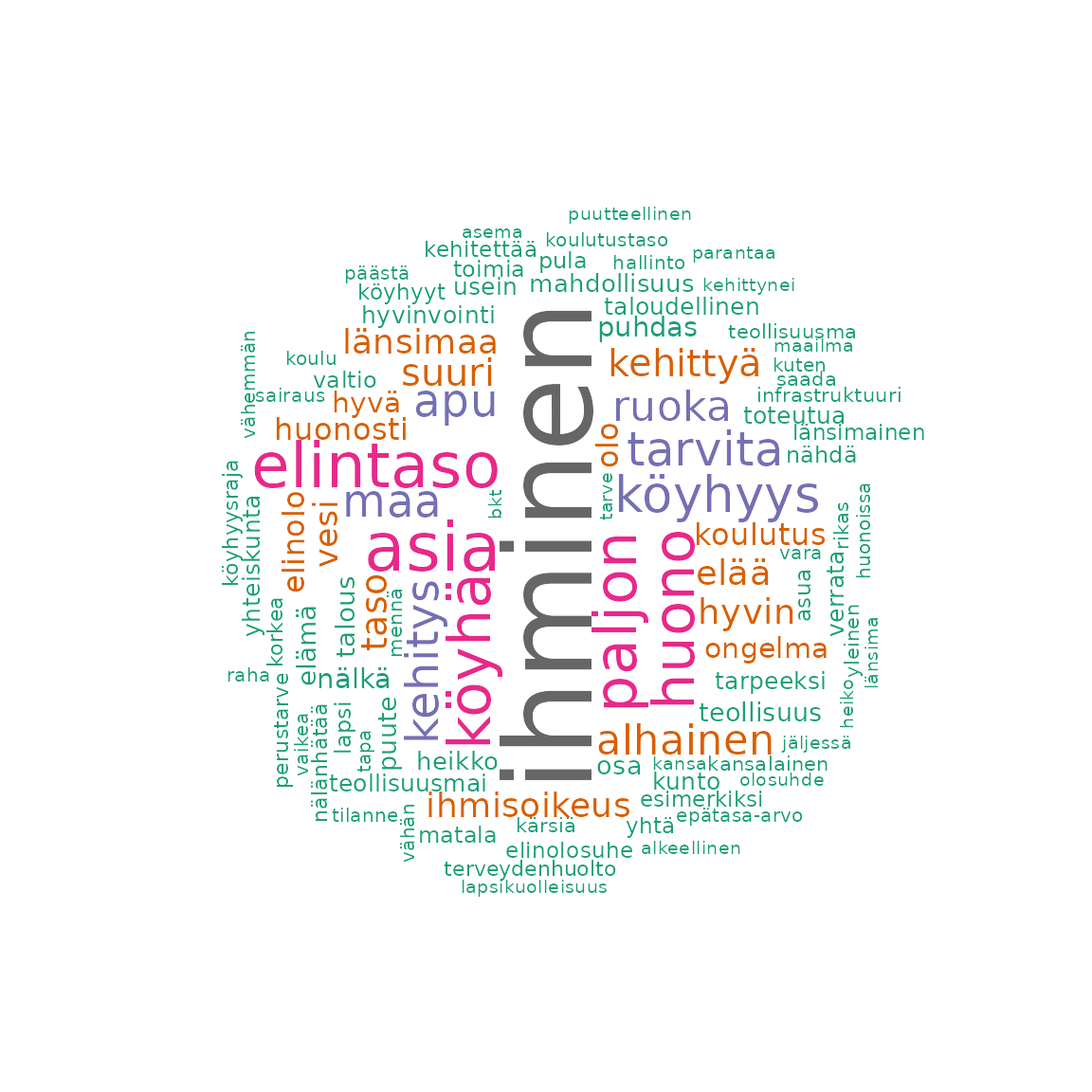
Wordcloud
We can see the most frequent words identified above also coming out in the wordclouds.
fst_wordcloud(
data = q11_1,
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
max = 100
)
fst_wordcloud(
data = q11_2,
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
max = 100
)
fst_wordcloud(
data = q11_3,
pos_filter = c("NOUN", "VERB", "ADJ", "ADV"),
max = 100
)
Exploring some concept networks based on thematic frequently occurring words
Based on the most frequently-occurring words, we have chosen some
lists of “concepts” for each question and will create Concept Networks
based on these. You can see below how the threshold can be
used to make sure the concept network isn’t too “busy” by removing less
frequent connection words. Similarly, you can see how the length of the
“concepts” list impacts the “busyness” of the plot. Often, the “concept”
list and appropriate threshold will be the product of trial
and error.
Q11_1
- q11_1 Jatka lausetta: Kehitysmaa on maa, jossa… (Avokysymys)
- q11_1 Continue the sentence: A developing country is a country where… (Open question)
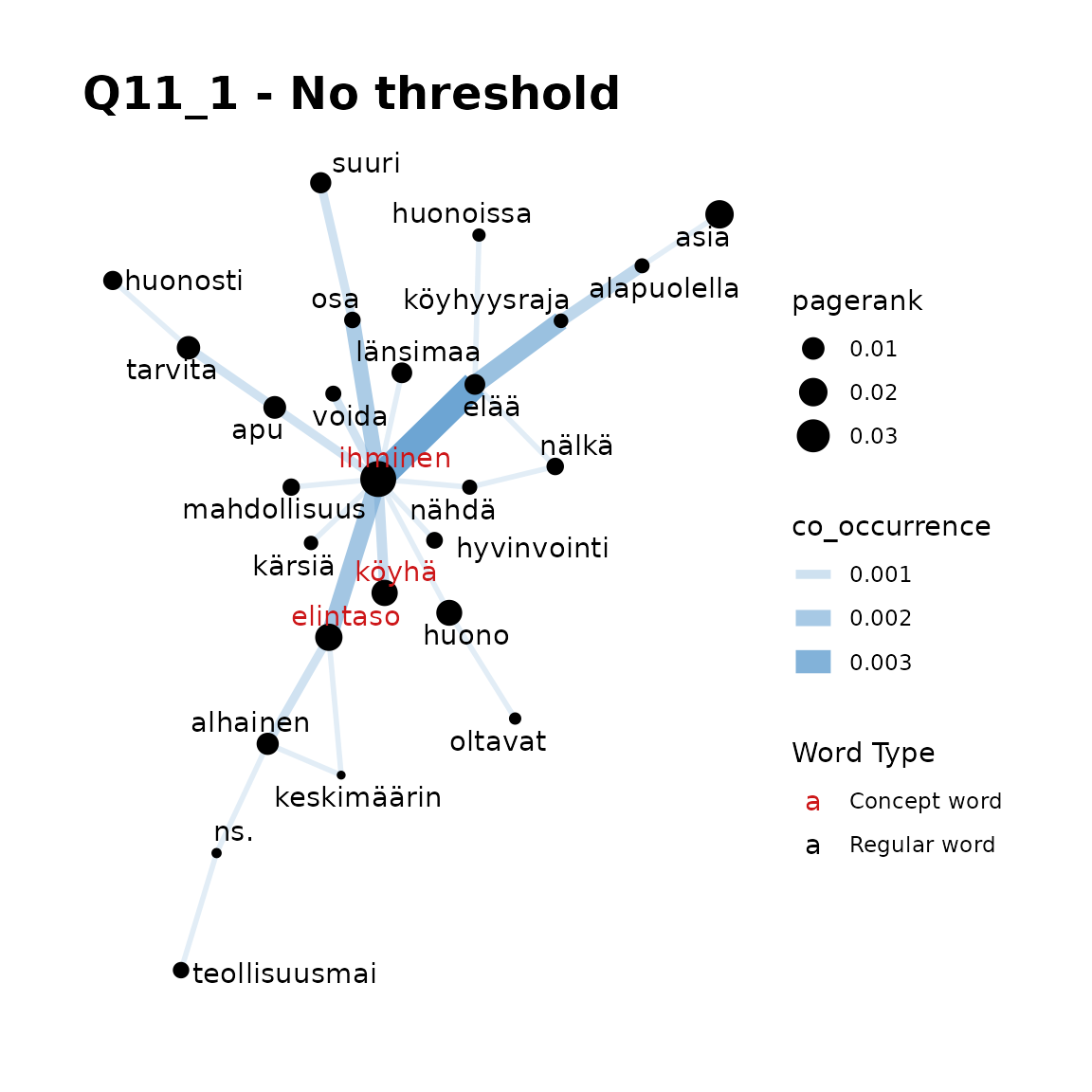
- Chosen concept words : “elintaso, köyhä, ihminen”
- (In English) standard of living, poor, man
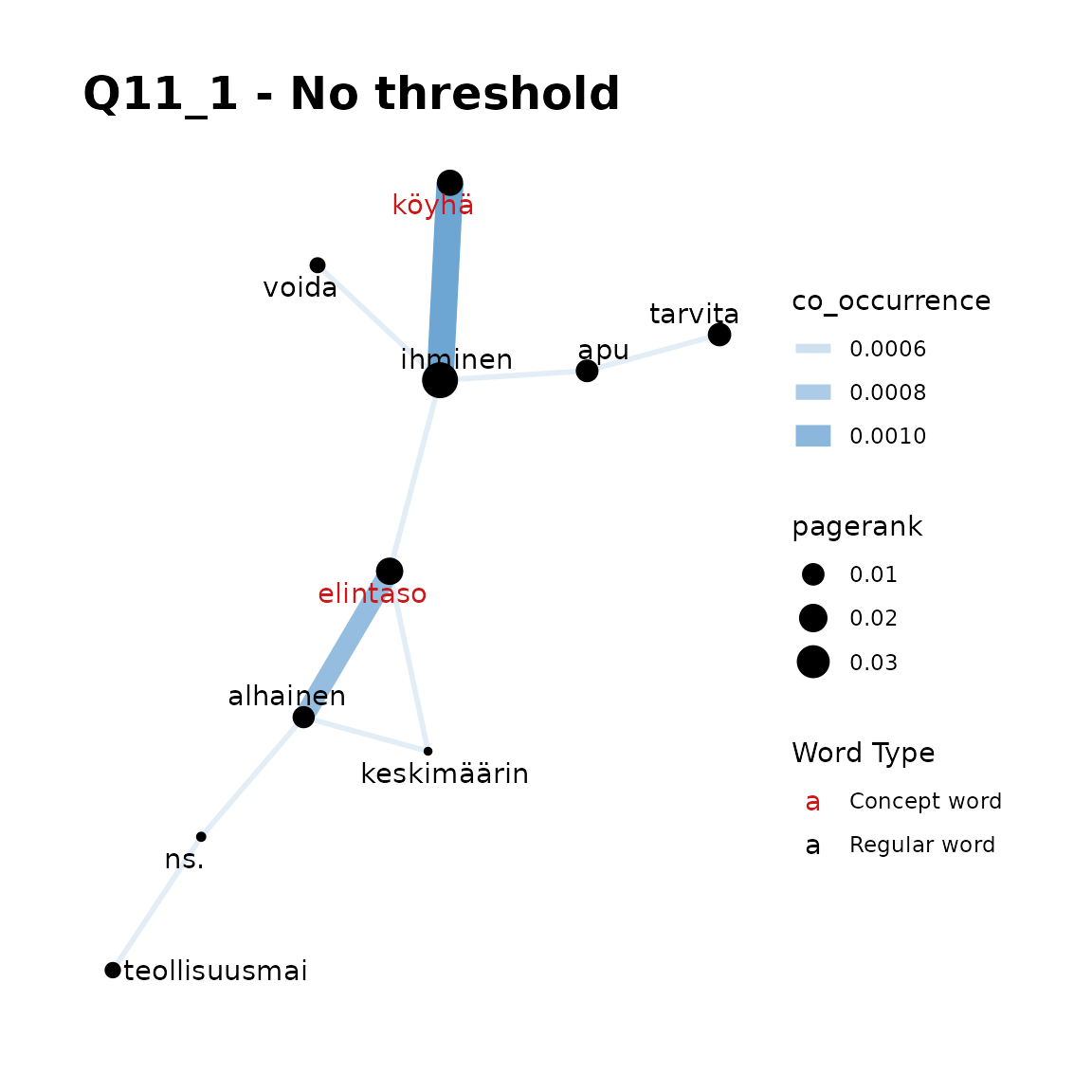
fst_concept_network(
data = q11_1,
concepts = "elintaso, köyhä",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_1 - No threshold"
)
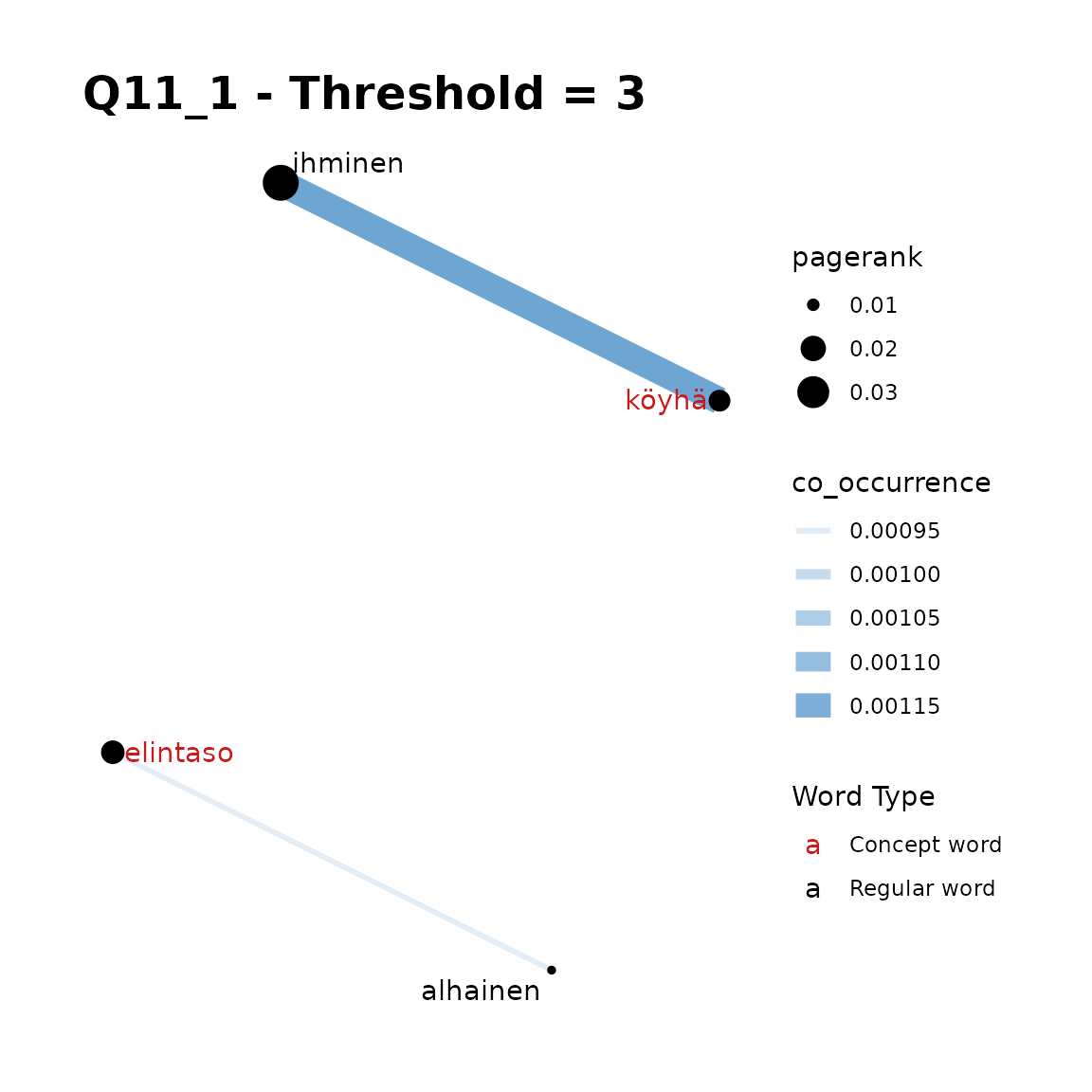
fst_concept_network(
data = q11_1,
concepts = "elintaso, köyhä",
threshold = 3,
norm = "number_words",
pos_filter = NULL,
title = "Q11_1 - Threshold = 3"
)
fst_concept_network(
data = q11_1,
concepts = "elintaso, köyhä, ihminen",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_1 - No threshold"
)
fst_concept_network(
data = q11_1,
concepts = "elintaso, köyhä, ihminen",
threshold = 3,
norm = "number_words",
pos_filter = NULL,
title = "Q11_1 - Threshold = 3"
)
Remarks:
Here, our first plot may be the best. We can see that a threshold is not required as there are not too many words displayed but we can get some insight into the use of these words (in English, they are ‘standard-of-living’ and ‘poor’). As you can see in plots 3 and 4, when including the most common word, ‘ihminen’ (‘human being’ or ‘man’), a threshold such as 3 is advisable.
Q11_2
- q11_2 Jatka lausetta: Kehitysyhteistyö on toimintaa, jossa…
(Avokysymys)
- q11_2 Continue the sentence: Development cooperation is an activity in which… (Open question)
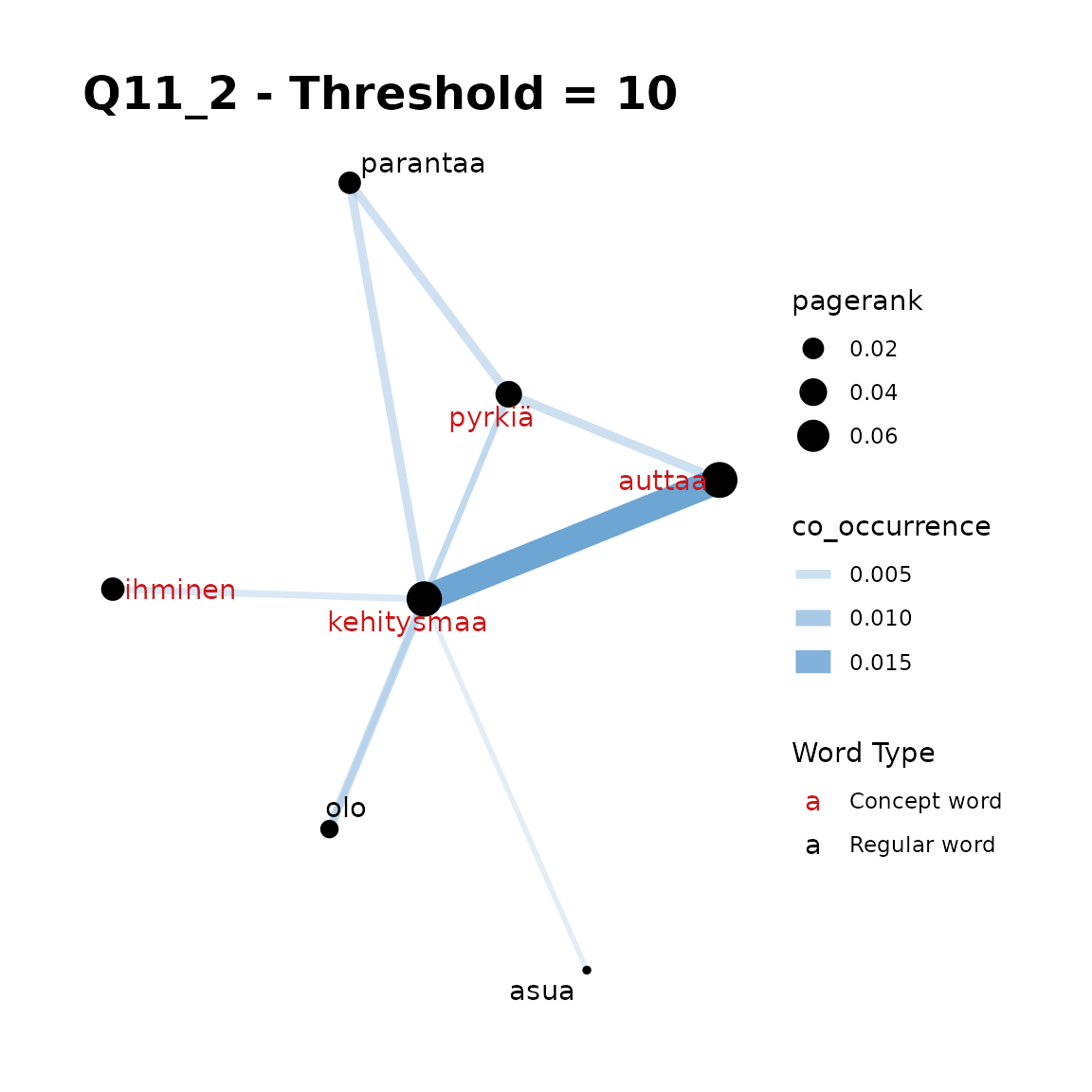
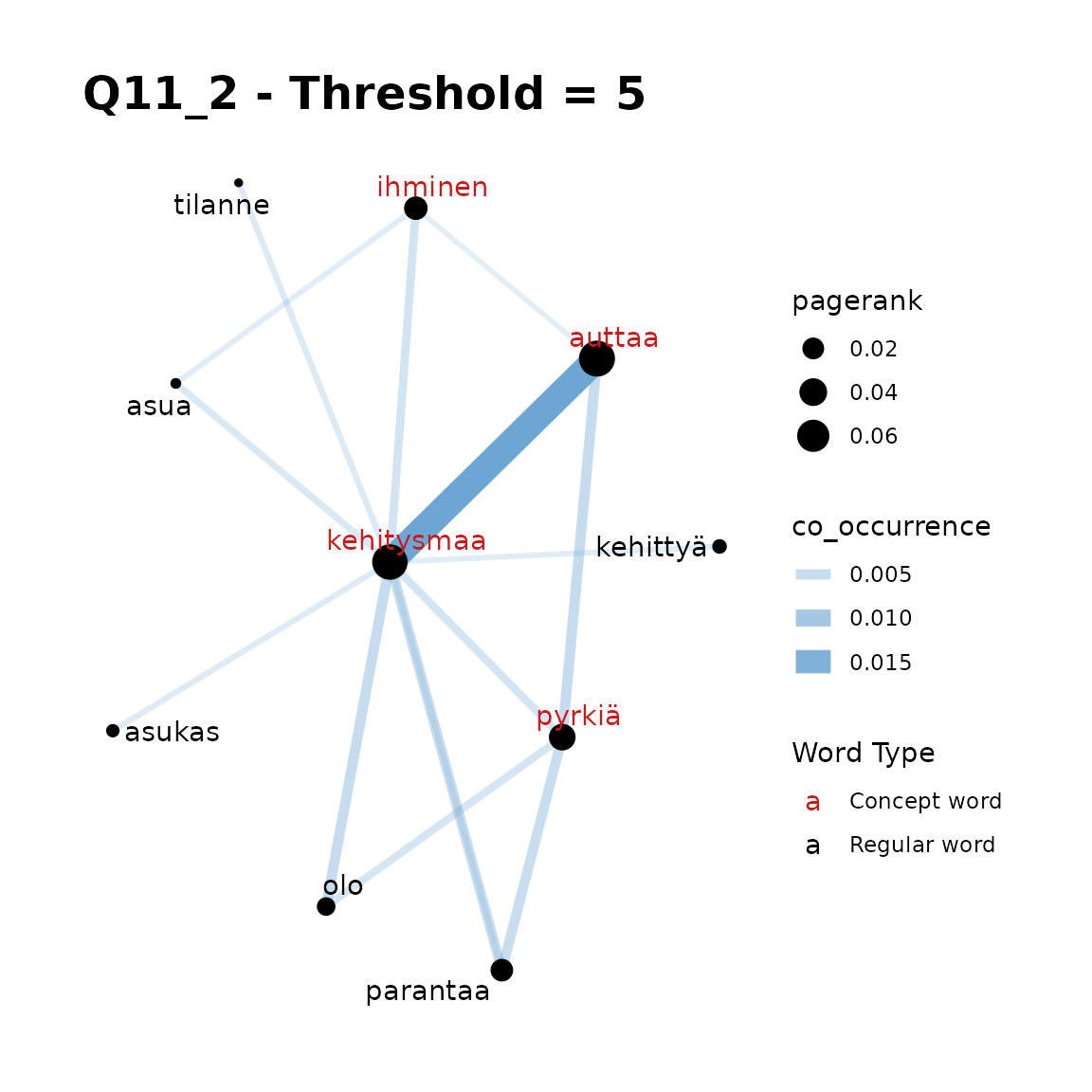
- Chosen concept words: “kehitysmaa, auttaa, pyrkiä, maa, ihminen”
- (In English) development, help, strive, country, man
fst_concept_network(
data = q11_2,
concepts = "kehitysmaa, auttaa, pyrkiä, maa, ihminen",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_2 - No threshold"
)
fst_concept_network(
data = q11_2,
concepts = "kehitysmaa, auttaa, pyrkiä, maa, ihminen",
threshold = 10,
norm = "number_words",
pos_filter = NULL,
title = "Q11_2 - Threshold = 10"
)
fst_concept_network(
data = q11_2,
concepts = "kehitysmaa, auttaa, pyrkiä, maa, ihminen",
threshold = 5,
norm = "number_words",
pos_filter = NULL,
title = "Q11_2 - Threshold = 5"
)
fst_concept_network(
data = q11_2,
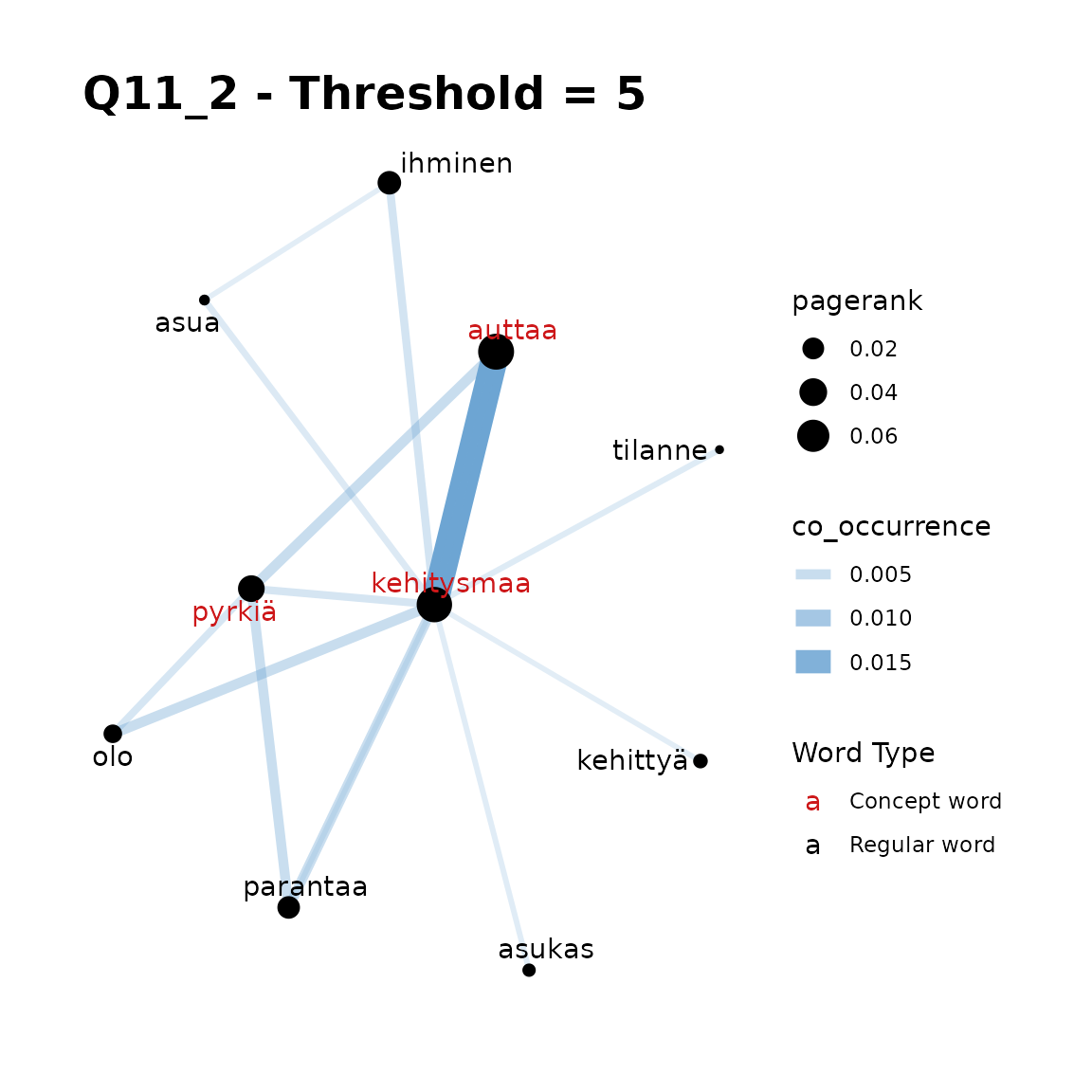
concepts = "kehitysmaa, auttaa, pyrkiä",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_2 - No threshold"
)
fst_concept_network(
data = q11_2,
concepts = "kehitysmaa, auttaa, pyrkiä",
threshold = 5,
norm = "number_words",
pos_filter = NULL,
title = "Q11_2 - Threshold = 5"
)
Remarks:
In Q11_2, plots 1-3 show that if we include all 5 of our words
(‘developing country’, ‘help’, ‘strive’, ‘country’, ‘man’) or a subset
that a threshold is required, but that a threshold of 10 is too large to
gain additional words in the Network. Here threshold = 5
seems appropriate.
Q11_3
- q11_3 Jatka lausetta: Maailman kolme suurinta ongelmaa ovat…
(Avokysymys)
- q11_3 Continue the sentence: The world’s three biggest problems are… (Open question)
- Chosen conpcet words: “köyhyys, nälänhätä, sota, ilmastonmuutos,
puute”
- (In English) poverty, famine, war, climate change, lack of
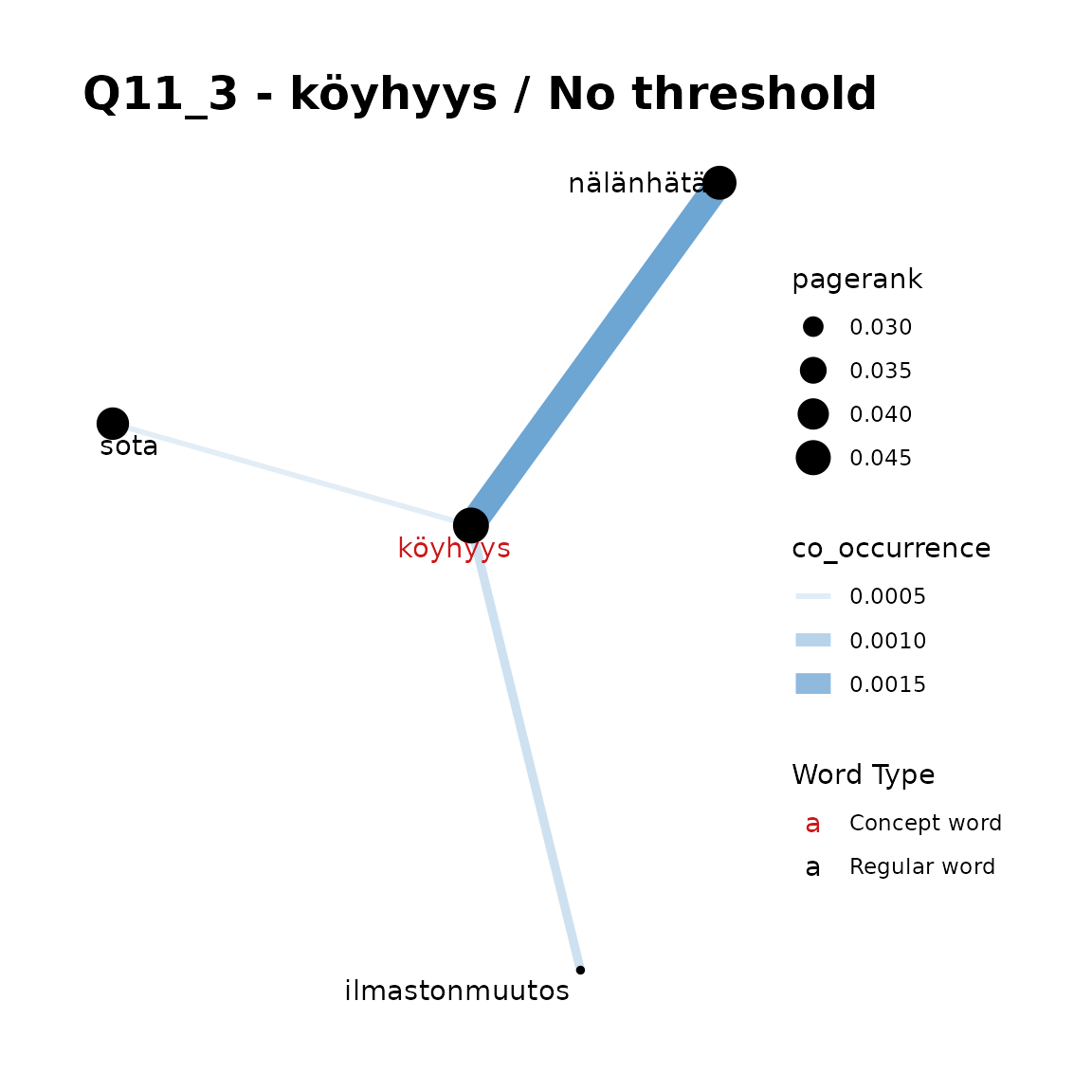
fst_concept_network(
data = q11_3,
concepts = "köyhyys",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_3 - köyhyys / No threshold"
)
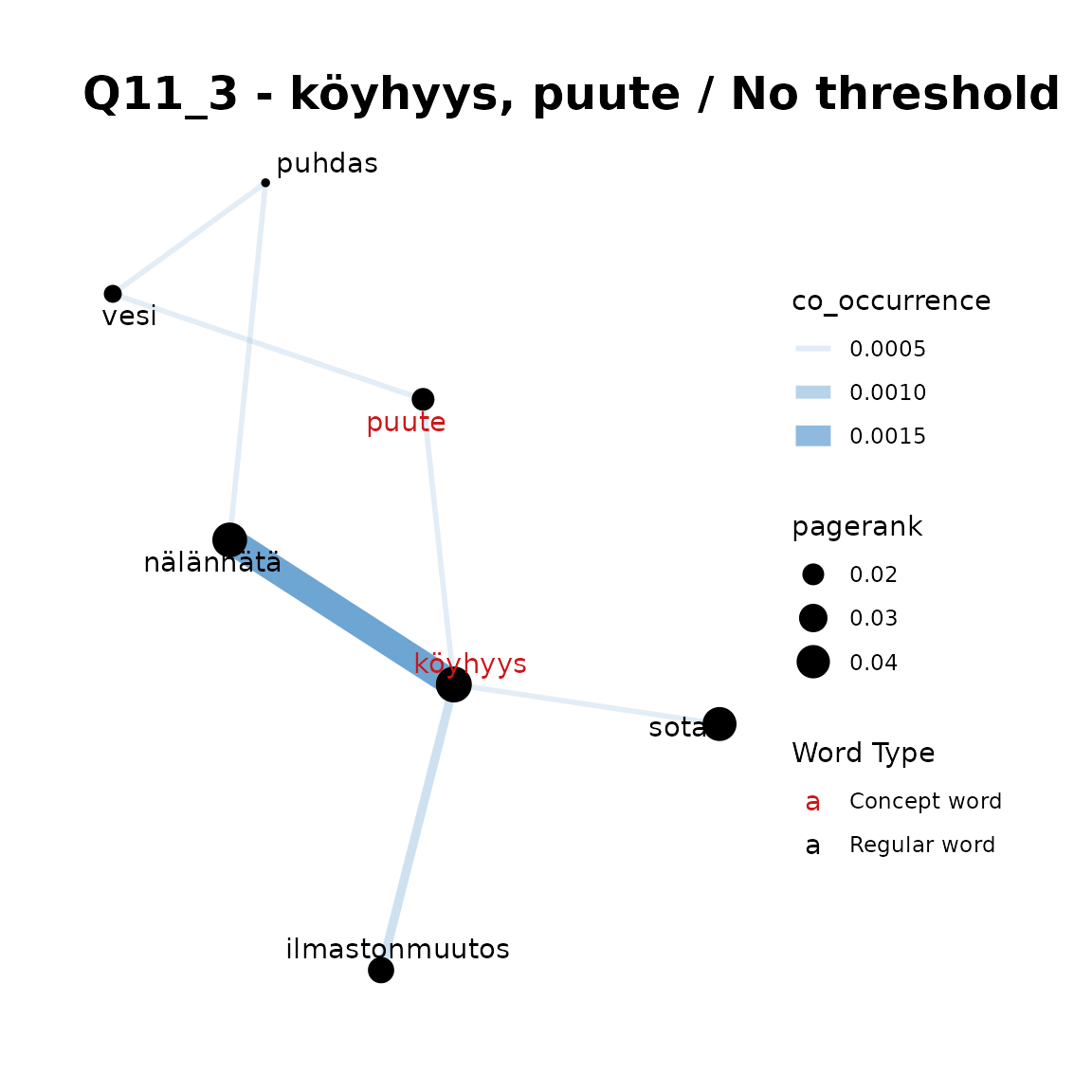
fst_concept_network(
data = q11_3,
concepts = "köyhyys, puute",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_3 - köyhyys, puute / No threshold"
)
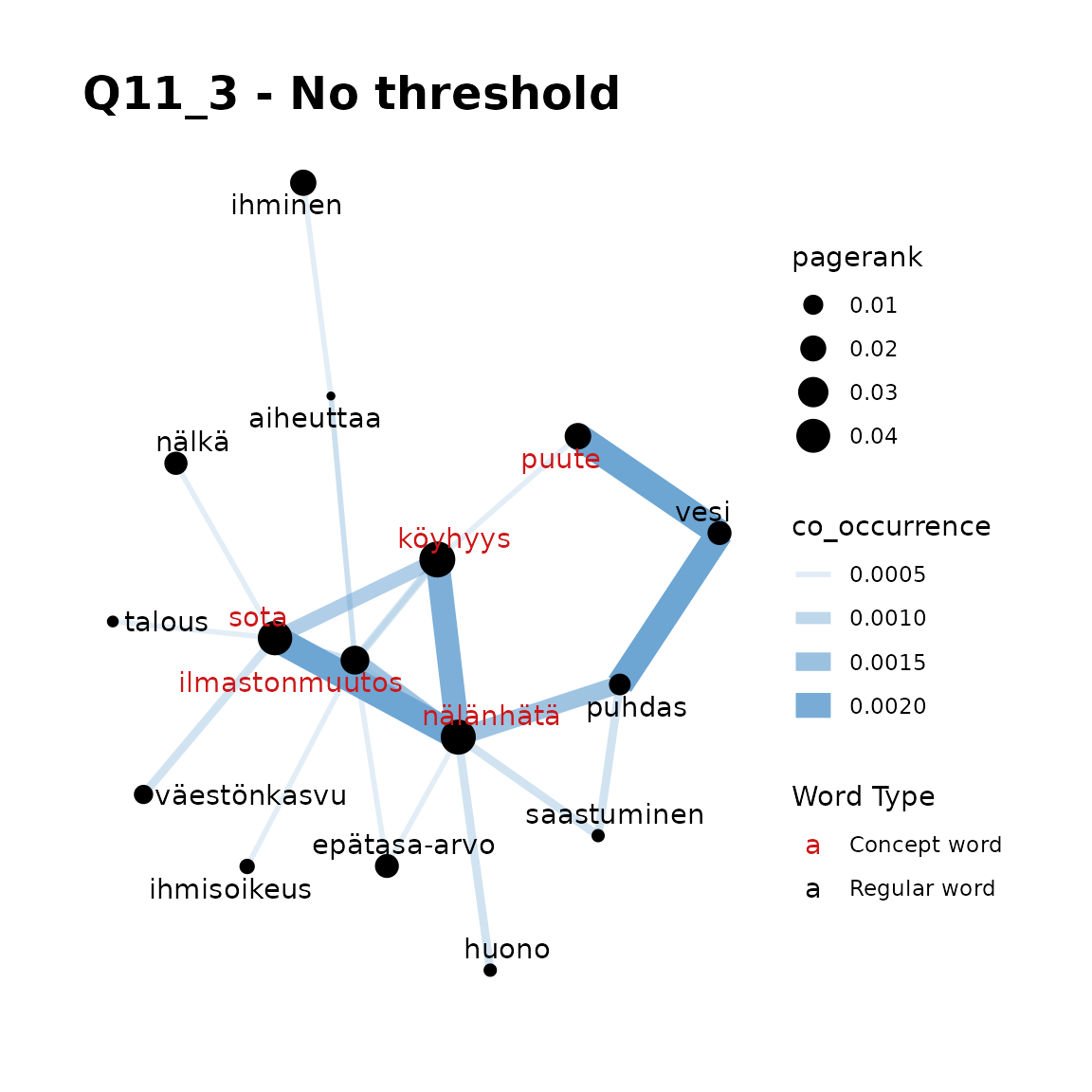
fst_concept_network(
data = q11_3,
concepts = "köyhyys, nälänhätä, sota, ilmastonmuutos, puute",
threshold = NULL,
norm = "number_words",
pos_filter = NULL,
title = "Q11_3 - No threshold"
)
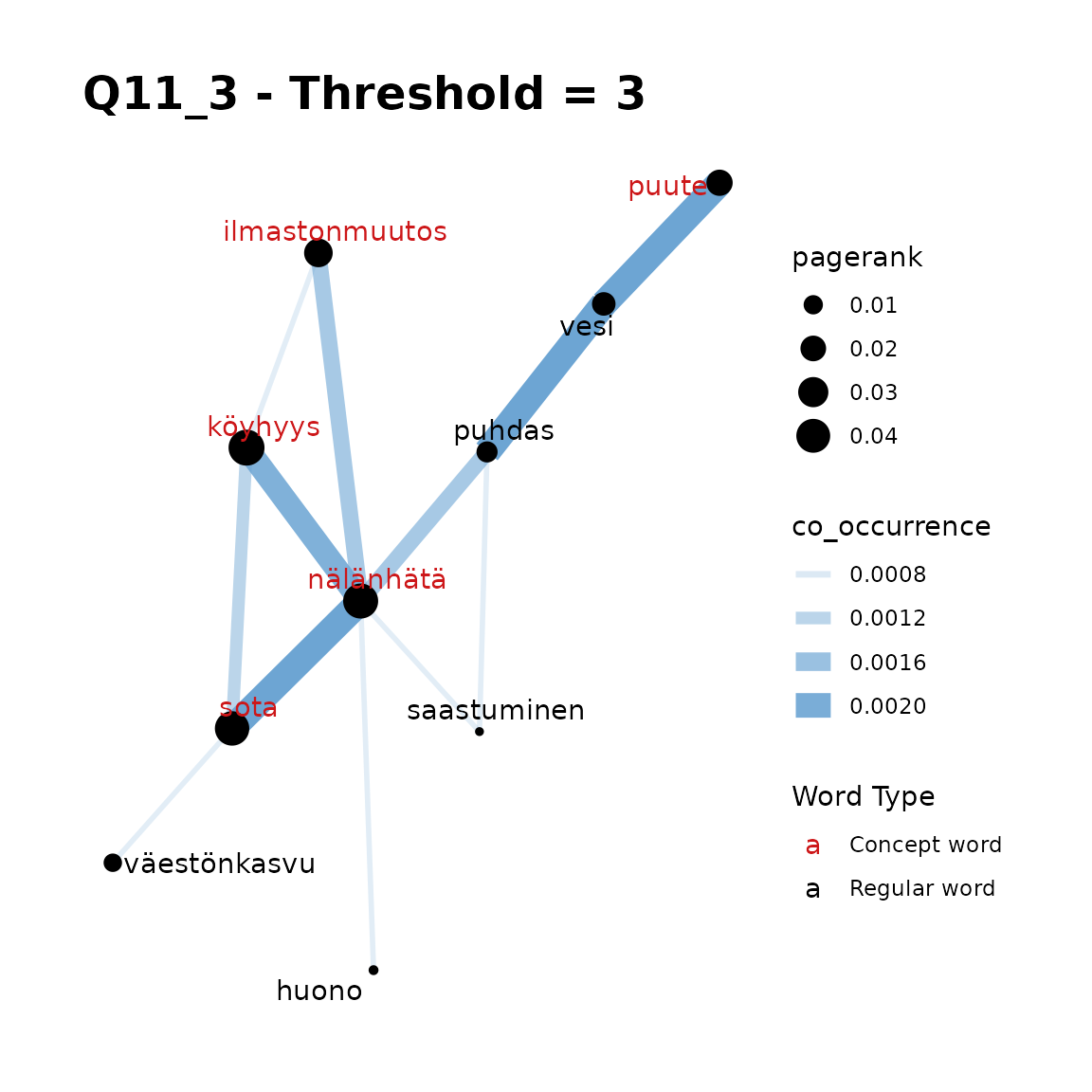
fst_concept_network(
data = q11_3,
concepts = "köyhyys, nälänhätä, sota, ilmastonmuutos, puute",
threshold = 3,
norm = "number_words",
pos_filter = NULL,
title = "Q11_3 - Threshold = 3"
)
fst_concept_network(
data = q11_3,
concepts = "köyhyys, nälänhätä, sota, ilmastonmuutos, puute",
threshold = 2,
norm = "number_words",
pos_filter = NULL,
title = "Q11_3 - Threshold = 2"
)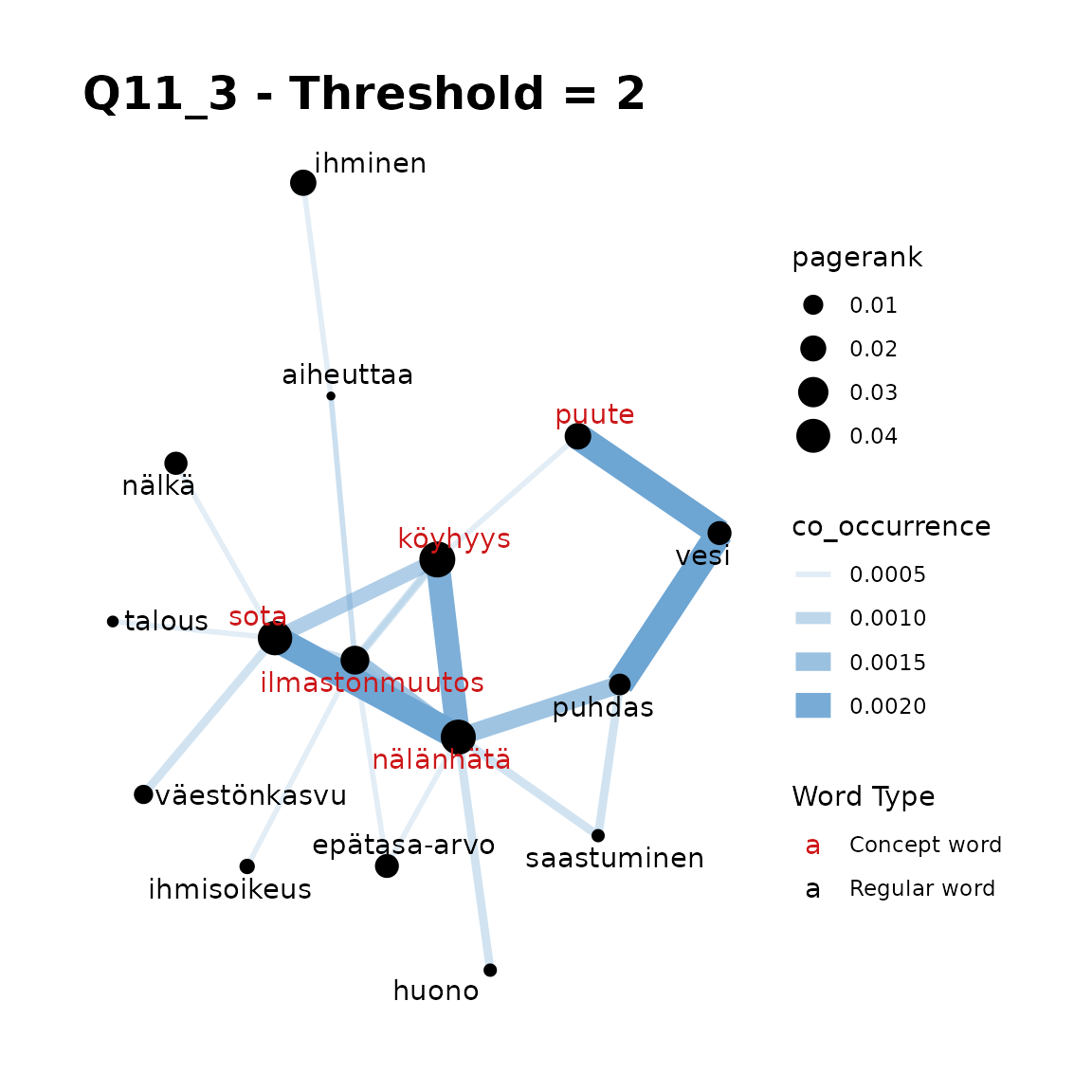
Remarks:
In Q11_3, we can see that if your concept word list is short (such as
a single word) thresholds generally are not required, but that with
longer concept lists, setting a threshold = 2 or
threshold = 3, we can simplify and improve a plot that is a
little too crowded in this case. The “best” threshold is generally a
matter of context and at the analyst’s discretion.
Conclusion
From the above, we can see that different settings create different
Concept Networks. There is no “right” setting for a Concept Network, so
it is worthwhile exploring the Concept Networks that result from
different concept words and thresholds to investigate the data and
identify trends which warrant further analysis. Initial Concept Network
settings can be informed by other functions in
finnsurveytext, such as choosing the most frequent
words/n-grams or considering insights from wordclouds.
Citation
Finnish Children and Youth Foundation: Young People’s Views on Development Cooperation 2012 [dataset]. Version 2.0 (2019-01-22). Finnish Social Science Data Archive distributor]. http://urn.fi/urn:nbn:fi:fsd:T-FSD2821