Creates a plot of the most frequently-occurring n-grams within the data. Optionally, weights can be provided either through a `weight` column in the formatted data, or from a `svydesign` object with the raw (preformatted) data.
Usage
fst_ngrams(
data,
number = 10,
ngrams = 1,
norm = NULL,
pos_filter = NULL,
strict = TRUE,
name = NULL,
use_svydesign_weights = FALSE,
id = "",
svydesign = NULL,
use_column_weights = FALSE
)Arguments
- data
A dataframe of text in CoNLL-U format, with optional additional columns.
- number
The number of top words to return, default is `10`.
- ngrams
The type of n-grams, default is `1`.
- norm
The method for normalising the data. Valid settings are `"number_words"` (the number of words in the responses, default), `"number_resp"` (the number of responses), or `NULL` (raw count returned).
- pos_filter
List of UPOS tags for inclusion, default is `NULL` which means all word types included.
- strict
Whether to strictly cut-off at `number` (ties are alphabetically ordered), default is `TRUE`.
- name
An optional "name" for the plot to add to title, default is `NULL`.
- use_svydesign_weights
Option to weight words in the plot using weights from a `svydesign` containing the raw data, default is `FALSE`
- id
ID column from raw data, required if `use_svydesign_weights = TRUE` and must match the `docid` in formatted `data`.
- svydesign
A `svydesign` which contains the raw data and weights, required if `use_svydesign_weights = TRUE`.
- use_column_weights
Option to weight words in the plot using weights from formatted data which includes addition `weight` column, default is `FALSE`
Examples
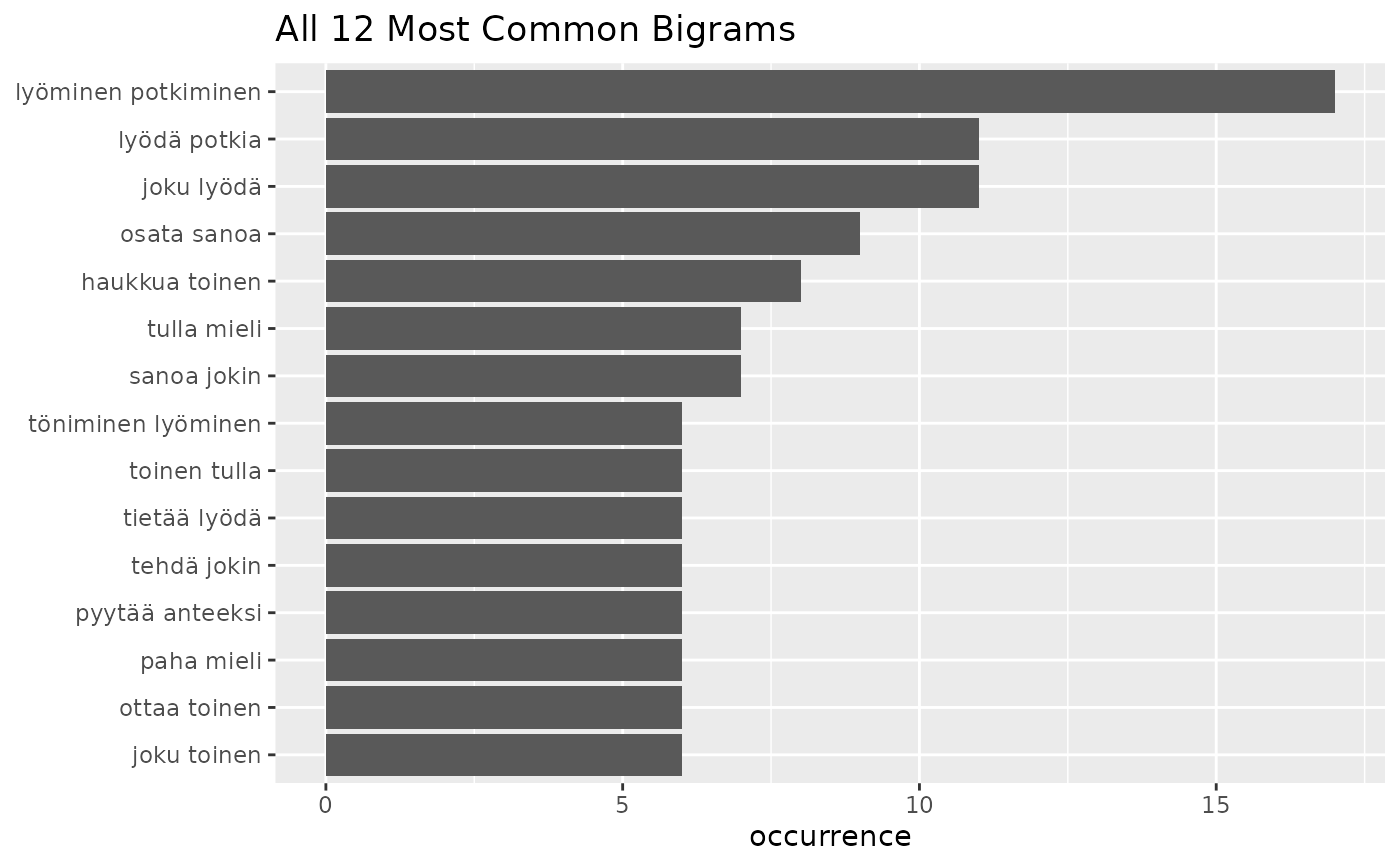
fst_ngrams(fst_child, 12, ngrams = 2, strict = FALSE, name = "All")
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> With `strict` = FALSE, n-grams occurring equally often as the `number` cutoff n-gram will be displayed.
#>
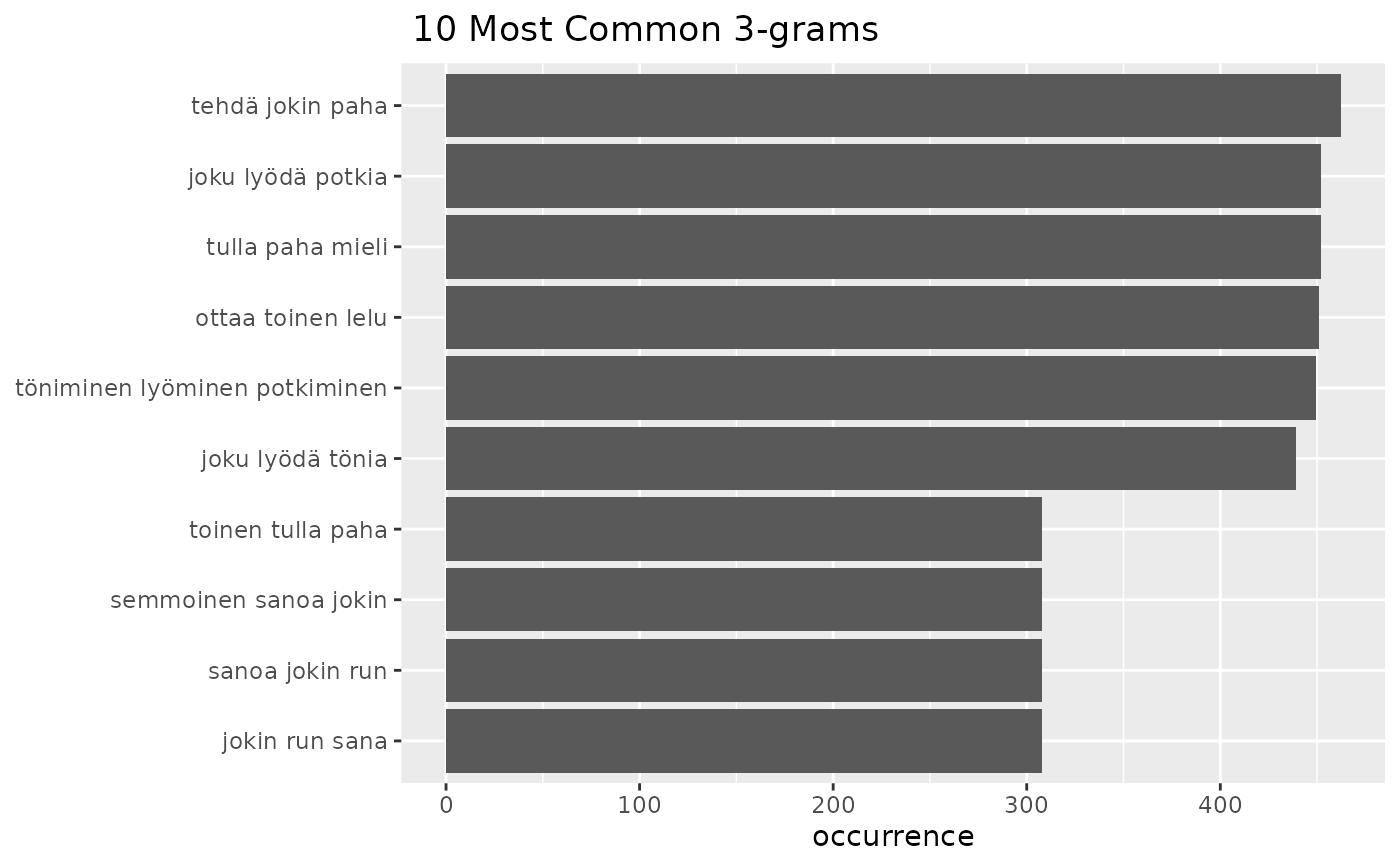
 c <- fst_child_2
s <- survey::svydesign(id=~1, weights= ~paino, data = child)
i <- 'fsd_id'
T <- TRUE
fst_ngrams(c, ngrams = 3, use_svydesign_weights = T, svydesign = s, id = i)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.
#>
c <- fst_child_2
s <- survey::svydesign(id=~1, weights= ~paino, data = child)
i <- 'fsd_id'
T <- TRUE
fst_ngrams(c, ngrams = 3, use_svydesign_weights = T, svydesign = s, id = i)
#> Note:
#> N-grams with equal occurrence are presented in alphabetical order.
#> By default, n-grams are presented in order to the `number` cutoff n-gram.
#> This means that equally-occurring later-alphabetically n-grams beyond the cutoff n-gram will not be displayed.
#>