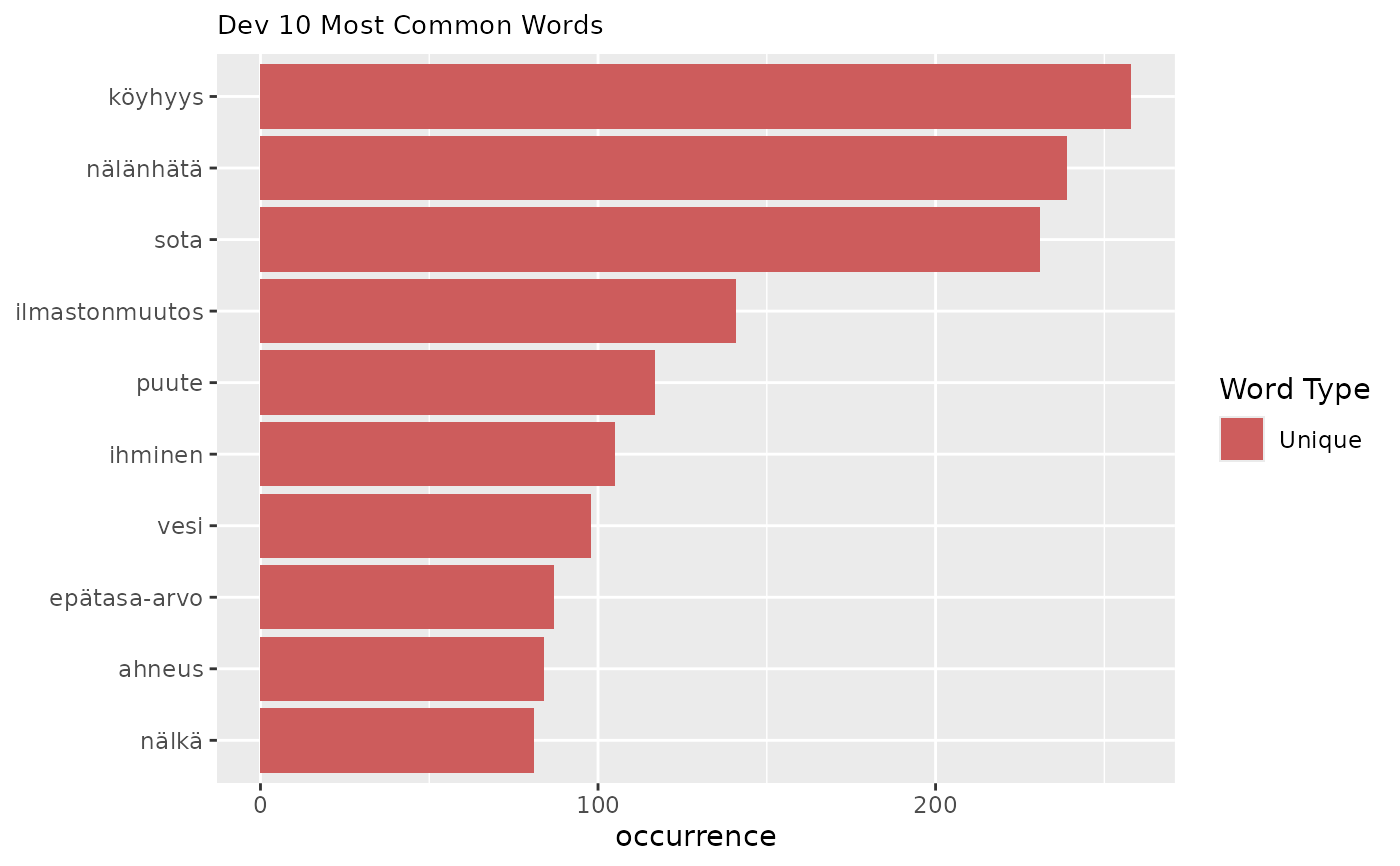
Plots frequency n-grams with unique n-grams highlighted.
Usage
fst_ngrams_compare_plot(
table,
number = 10,
ngrams = 1,
unique_colour = "indianred",
name = NULL,
override_title = NULL,
title_size = 20
)Arguments
- table
The table of n-grams, output of `get_unique_ngrams()`.
- number
The number of n-grams, default is `10`.
- ngrams
The type of n-grams, default is `1`.
- unique_colour
Colour to display unique words, default is `"indianred"`.
- name
An optional "name" for the plot, default is `NULL`.
- override_title
An optional title to override the automatic one for the plot. Default is `NULL`. If `NULL`, title of plot will be `number` "Most Common 'Term'". 'Term' is "Words", "Bigrams", or "N-Grams" where N > 2.
- title_size
size to display plot title
Examples
top_child <- fst_freq_table(fst_child)
#> Note:
#> Words with equal occurrence are presented in alphabetical order.
#> By default, words are presented in order to the `number` cutoff word.
#> This means that equally-occurring later-alphabetically words beyond the cutoff word will not be displayed.
#>
top_dev <- fst_freq_table(fst_dev_coop)
#> Note:
#> Words with equal occurrence are presented in alphabetical order.
#> By default, words are presented in order to the `number` cutoff word.
#> This means that equally-occurring later-alphabetically words beyond the cutoff word will not be displayed.
#>
unique_words <- fst_get_unique_ngrams_separate(top_child, top_dev)
top_child_u <- fst_join_unique(top_child, unique_words)
top_dev_u <- fst_join_unique(top_dev, unique_words)
fst_ngrams_compare_plot(top_child_u, ngrams = 1, name = "Child")
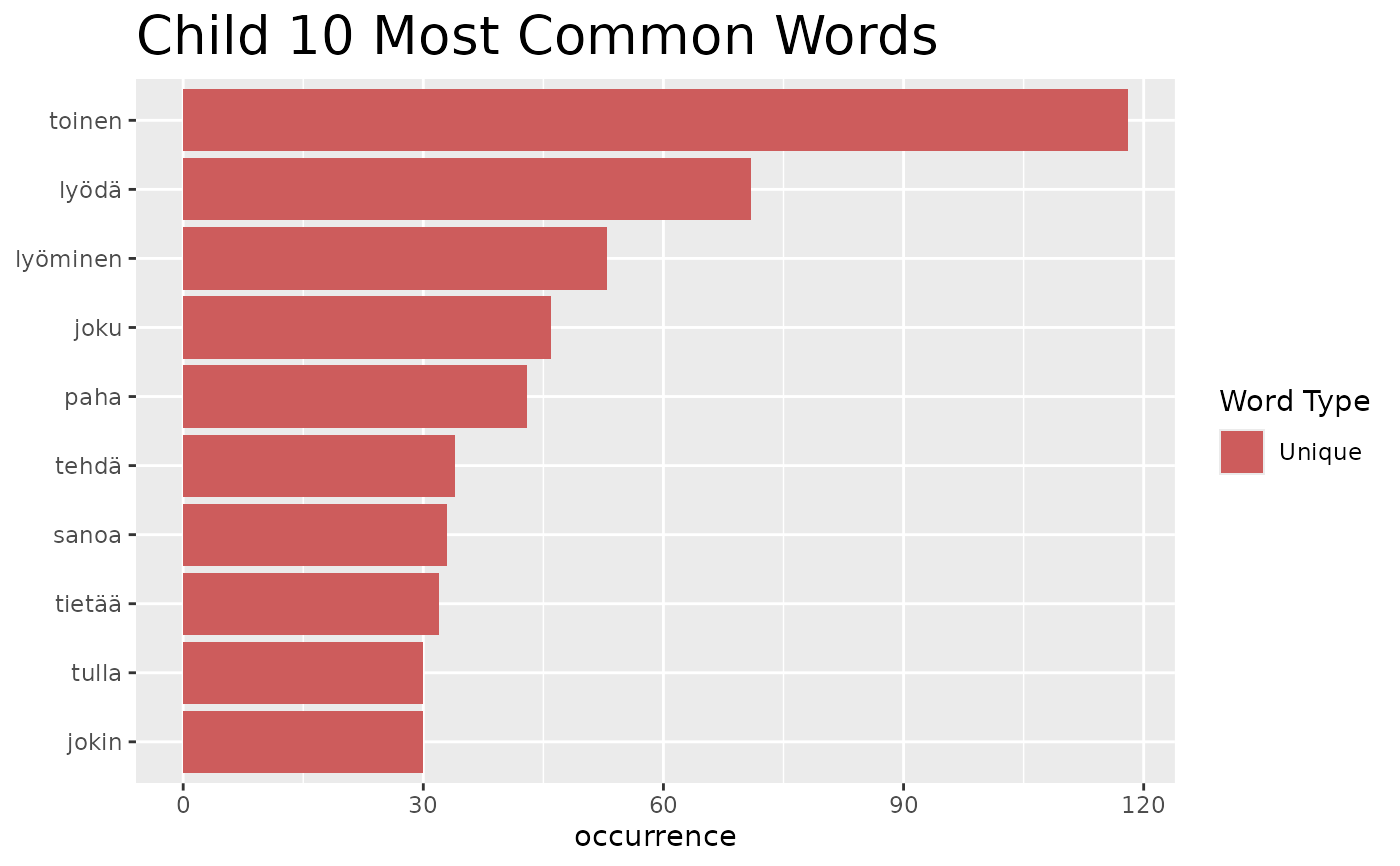 fst_ngrams_compare_plot(top_dev_u, ngrams = 1, name = "Dev", title_size = 10)
fst_ngrams_compare_plot(top_dev_u, ngrams = 1, name = "Dev", title_size = 10)